
Now Loading ...
-
Cookie
쿠키 개요
쿠키는 서버가 클라이언트에게 특정 정보를 저장하도록 전달하는 수단으로, 서버가 HTTP 응답에 쿠키를 포함하면 이후 클라이언트는 서버와의 요청마다 해당 쿠키를 함께 전송한다.
이 용어는 원래 유닉스·네트워크 시스템에서 프로세스 간 통신 시 신원 식별이나 권한 확인을 위해 주고받던 작은 데이터 조각인 매직 쿠키(Magic Cookie) 개념에서 비롯되었다. 이러한 아이디어를 웹에 적용하면서, HTTP 통신에서도 클라이언트와 서버가 교환하는 작은 데이터 조각이라는 공통된 특성을 반영해 쿠키라 불리게 되었다.
실제 사용 예로는 로그인 상태 유지(세션 관리), 장바구니와 같은 사용자 활동 기록, 언어·테마 설정과 같은 개인화, 그리고 광고나 분석을 위한 사용자 행동 추적 등이 있다.
브라우저 저장소
브라우저가 인증 등에 사용하는 정보들을 저장하기 위한 방법론에는 쿠키, 로컬 스토리지, 세션 스토리지, 웹 스토리지 등이 있다.
각 저장소에 대한 간략한 설명은 아래와 같다.
쿠키
쿠키란 서버가 클라이언트에게 보내는 작은 데이터 파일로, 서버가 쿠키를 브라우저에게 적용을 시키면 그 이후 서버와 클라이언트에 모든 요청과 응답에는 쿠키가 포함되어 전송된다. 이러한 특징 때문에 저장할 수 있는 용량이 작으며 보안의 취약하다는 단점이 있다.
로컬 스토리지
브라우저 자체에 영구적으로 데이터를 저장하고, 브라우저가 종료되더라도 데이터가 유지가 된다.
로컬 스토리지 세팅 예시
세션 스토리지
탭 윈도우 단위로 스토리지가 생성이 되며, 탭 윈도우를 닫을 때 데이터가 삭제되는 특징을 가진다. 페이지 새로고침으론 데이터가 삭제되지 않는다.
세션 스토리지 세팅 예시
로컬이나 세션 스토리지의 경우, CrossSite 공격에 취약하기 때문에 민감한 정보를 저장하면 안된다.(SOP 정책이 있는 이유인 공격에 취약)
또한 JS를 통해 데이터에 접근하며 쿠키와 다르게 항상 붙여져서 서버에 전송되지 않는다.
쿠키의 구성
response.set_cookie(
key="access_token",
value=token.access_token,
httponly=True,
secure=True, # dev use only https
samesite="None",
max_age=ACCESS_TOKEN_EXPIRE_MINUTES * 60,
)
위와 같은 예시로 쿠키를 서버가 설정하여 브라우저가 특정 쿠키를 저장하도록 설정할 수 있다.
이때 쿠키에 적용될 수 있는 옵션들은 아래와 같은 의미를 갖는다.
참고링크
1. Key & value
쿠키에 저장되는 정보는 기본적으로 key와 value의 쌍으로 저장되며, 각 쿠키는 브라우저와 통신하는 서버별로 따로 저장된다.
만약 여러 개의 key, value를 저장하고 싶다면 각 key, value별로 옵션을 설정하여 set_cookie를 실행해야한다.
2. Domain
쿠키를 보낼 호스트를 정의하는 옵션이다.
쿠키는 쿠키가 생성된 도메인 별로 종속되어서 저장된다. 예를 들어 example.com에서 생성된 쿠키는 www.example.com에선 사용될 순 있지만, 반대로 www.example.com에서 생성된 쿠키는 example.com에선 사용될 수 없다.
이런 식으로 쿠키가 저장될 도메인을 설정할 옵션은 자신과 관련된 서브 도메인까지만 가능하다.
예를 들어 우리의 주소 dev.medai.im 도메인에서 쿠키를 설정할 땐 해당 옵션을 사용하여 medai.im 도메인에 쿠키를 저장하여 다른 서브 도메인들에서 해당 쿠키를 사용하게 만들 순 있지만, 다르게 ai.im 같은 전혀 다른 도메인에 쿠키를 저장할 순 없다.
3. Expires, max_age : 쿠키의 만료시간과 관련된 옵션
이 두가지 옵션은 쿠키가 유지되는 시간을 정의하는 옵션이다.
MaxAge : 쿠키가 유지되는 시간을 정의하며, 만약 Expires와 동시에 설정된다면 우선되는 옵션이다. 현재 시간에 해당 옵션의 시간이 추가되어 만료시간이 계산된다.
Expires : HTTP Date형식으로 쿠키가 만료되는 날짜와 시간을 정의한다.
만약 2개의 옵션을 모두 설정하지 않으면, 쿠키는 브라우저가 종료되는 시점까지 유지되는데 이를 Session Cookie라고 한다.
4. HttpOnly, Secure : 쿠키의 보안과 관련된 옵션
HttpOnly : 해당 옵션을 활성화할 시, 쿠키를 JavaScript를 통해서 저장된 곳을 접근해 확인하는 것이 불가능해진다. 이 옵션이 true가 되었다면 개발자도구를 통해서 직접 확인하거나, 서버와 클라이언트가 통신 중 헤더에 붙은 쿠키를 직접 확인하는 방법으로만 체크할 수 있게 된다.
Secure : HTTP는 기본적으로 평문으로 통신하기에 쿠키 역시도 확인이 가능하다. 하지만 Secure 옵션이 존재하는 순간 http에 쿠키를 붙여서 보낼 수 없게되며, 오로지 https를 통해서 전송할 시에만 쿠키를 붙일 수 있게 된다.
5. Partitioned
쿠키는 기본적으로 요청을 받는 서버별로 브라우저가 쿠키를 저장한다. 이와 같은 특징으로 인해 만약 광고 tracker.com 이라는 사이트가 특정 js를 광고용으로 여러 사이트 a.com, b.com에 넣어두면, 브라우저가 a.com, b.com을 방문했을 때 같은 tracker.com으로 요청이 들어감으로써 쿠키를 통해 브라우저를 고유하게 식별해서 사용자 추적이 가능해진다.
이러한 사용자 추적을 막기위한 기능이 Partitioned로 쿠키를 저장한 버킷을 tracker.com으로만 두는 것이 아닌 탑레벨 사이트 + 쿠키 도메인으로 a.com, b.com도 쿠키 저장소를 구분하는 기준에 추가하여, 탑레벨 사이트만으로 쿠키가 공유되지 않도록 한다.
6. Path
해당 쿠키를 클라이언트-서버가 통신할 때 전부 붙여서 보내는 게 아닌,
Path=/target-path로 설정하면 www.example.com/other-path 같은 url에선 쿠키가 전송되지 않고, www.example.com/target-path 및 해당 url의 하위 경로로 요청을 보낼때만 브라우저가 쿠키를 포함시킨다.
7. SameSite
Strict, Lax, None 3가지 옵션을 가질 수 있으며 각 옵션의 의미는 아래와 같다.
Strict
브라우저가 동일한 사이트 요청에만 쿠키를 전송한다. 예를 들어 www.a-example.com에서 백엔드인 www.be-example.com으로 요청을 보내 백엔드에서 쿠키를 설정해 보낸다면, 2개의 사이트의 도메인이 다르기에 Strict 옵션을 사용한 쿠키라면 저장이 되지 않는다.
만약 a-example.com에서 api.a-example.com 백엔드로 보낸다면 2개의 사이트의 도메인이 같기에 Strict 옵션을 통과하고 저장된다.
이때 동일한 사이트로 구분되는 기준은 Public Domain과 앞의 접미사까지 동일해야 동일한 사이트로 취급된다. public domain 리스트
ex) .com, .github.io 등 Public Domain에 대해 그 다음 항목인 a.com a.github.io | b.com b.github.io 는 다른 사이트이다.
Lax
Lax 옵션은 SameSite가 아니더라도, 특정 접근에 관해서는 쿠키를 붙이는 것을 허용하는 옵션이다. 여기서 특정 접근은 아래와 같다.
사용자가 직접 사이트에서 클릭을 해서 이동하는 경우
해당하는 내용은 특정 이미지 등의 리소스 요청이 아닌 전체 사이트가 변경되는 GET 요청(특정 사이트에서 동일한 로그인 정보를 공유하는 다른 사이트로 갈 때 등)에는 Lax 옵션을 통해 허용해준다.
None
오로지 Secure 옵션이 true 인 것과 병행될 때만 사용 가능한 옵션으로, 백엔드와 요청을 보낸 사이트가 samesite가 아니더라도 언제나 쿠키를 보낼 수 있는 옵션이다. 해당 옵션이 활성화되지 않는다면, 서버와 클라이언트의 도메인 주소가 다르다면 쿠키를 사용할 수 없다.
개발환경에서 localhost:3000에서 arna.medai.im으로 요청을 보낸다면 SameSite가 None이 아닌 경우 Cookie를 설정할 수 없다.
-
JWT
JWT 개요
JWT란 토큰의 일종으로, http 통신을 수행할 때 해당 토큰을 요청이나 응답의 일부로 넣어줌으로써 서버와 클라이언트가 상태유지를 수행할 수 있게 해주는 개념이다.
JWT는 header, payload, verify signature로 구성되어 JWT 토큰을 인코딩하고, 반대로 JWT 토큰을 디코딩하면 해당 값들을 획득할 수 있다.
이와 관련된 예시는 JWT 예시 사이트를 접속해 확인해보자
JWT 토큰 예시
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWUsImlhdCI6MTUxNjIzOTAyMn0.KMUFsIDTnFmyG3nMiGM6H9FNFUROf3wh7SmqJp-QV30
이렇게 구성된 토큰은 Based64Decode 등의 방법론을 통해서 encode, decode 가능하다. 즉 별도의 키가 필요한 해독방식은 아니다.
토큰을 살펴보면 .으로 구분된 3개의 영역이 있는데 이를 각각 디코딩을 수행하면 아래와 같은 정보들이 생성된다.
디코딩된 정보 예시
1. header
{
"alg": "HS256",
"typ": "JWT"
}
토큰의 타입(typ)는 보통 JWT로 고정되어있고, alg는 알고리즘의 약자로, 3번 서명값을 만드는데 사용될 알고리즘의 약자가 적혀있다.
2. payload
{
"sub": "1234567890",
"name": "John Doe",
"admin": true,
"iat": 1516239022
}
Json 형식으로 서비스가 사용자에게 해당 토큰을 통해 공개하기를 원하는 내용, 사용자 닉네임, 서비스 상의 레벨, 관리자 여부 등의 정보를 저장할 수 있는 부분이다. 이렇게 토큰에 담긴 사용자에 대한 정보를 Claim이라고 한다. 이렇게 사용자에 대한 정보를 애초에 포함한 정보가 보내지기에, 서버가 DB 등을 뒤질 필요성도 적어진다.
3. verify signature
a-string-secret-at-least-256-bits-long
해당 값에는 header + payload + 서버에 존재하는 비밀값을 기반으로 헤더에 적힌 암호화알고리즘을 통해 생성된 secret string 서명값이 기록되어있다. 별도의 키 값 없이 payload나 header가 해독되더라도, 그 값을 멋대로 수정해버리면 서버에 존재하는 비밀키 값과 조합되서 알고리즘을 실행시켰을 때 verify signature값이 달라져버리기에 JWT가 인증의 수단으로 사용될 수 있다.
JWT의 특징
위와 같은 JWT의 구성방식을 보면 알 수 있듯이, JWT의 기록되는 상태 정보는 시간에 따라 달라지는 것이 아닌 해당 인증이 유효할 때 항상 동일한 정보를 기반으로 사용자를 구분한다. 이런 식으로 시간에 따라 바뀌지 않는 상태값을 갖는 것을 stateless라고 불리며, 반대로 세션은 stateful이라고 불린다.
이러한 특징으로 인해
인증에 관련된 사용자의 상태정보가 시간에 따라 바뀌지 않는다.
서버가 사용자의 정보를 별도로 기록할 필요가 없기 때문에, 비용적인 측면에서 장점이 존재한다.
토큰이 탈취되면 서버는 이를 구분할 방법이 없기에, 탈취에 대한 대처가 취약하다.
토큰 탈취의 위험을 막기 위해 보통 refresh Token과 access Token을 따로 구현한 후 위에서 이야기한 인증에 관련된 기능은 유효기간이 짧은 access Token으로 refresh Token은 access Token을 재발급해줄 수 있는 역할과 이를 서버가 기억함으로써 서버가 로그인을 관리할 수 있도록 한다.
실제 구현(파이썬 프로젝트와 관련된 예시)
.env 등 공개되지 않는 환경설정 파일에서 아래와 같이 JWT에 사용될 서버가 저장하는 비밀키를 저장한다.
JWT_SECRET_KEY=~
파이썬 코드 내부에서 사용될 알고리즘과 Access Token 만료시간, refresh Token 만료시간을 저장한다.
SECRET_KEY = JWT_SECRET_KEY
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 4 * 60 # AccessToken 만료 시간
REFRESH_TOKEN_EXPIRE_DAYS = 14 # RefreshToken 만료 시간
로그인이 완료된 후 payload에 입력될 정보들을 서버에서 입력해주어 Access Token을 생성해준다.
new_access_token = create_access_token(
data={"sub": username}, expires_delta=access_token_expires
)
def create_access_token(data: dict, expires_delta: Union[timedelta , None] = None):
to_encode = data.copy()
print("to_encode", to_encode)
if expires_delta:
expire = datetime.now(timezone.utc) + expires_delta
else:
expire = datetime.now(timezone.utc) + timedelta(minutes=ACCESS_TOKEN_EXPIRE_MINUTES)
to_encode.update({"exp": expire})
encoded_jwt = jwt.encode(to_encode, SECRET_KEY, algorithm=ALGORITHM)
return encoded_jwt
현재 구현된 코드에선 사용자의 username과 access token이 만료되는 시간을 인증 payload에 넣은 모습을 볼 수 있다. AlGORITHM은 위에서 상수로 고정되어있으며, SECRET KEY는 .env파일을 통해 가져와서 jwt 코드를 인코딩해 Access Token을 사용하는 모습을 볼 수 있다.
또한 refresh Token은 서버에 저장해서 비교하는 용도이기 때문에, JWT만을 쓰지 않고 랜덤한 난수 등을 활용해 키를 만들 수도 있으면, 탈취되었다면 서버 DB에서 제거하는 등으로 대처할 수 있다.
다만 현재 구현되는 시스템은 병원의 내부망에서 사용될 예정이기에, 보안상 access Token의 탈취 위험이 적기에 현재는 별도의 refresh token을 사용하지 않게 변경되었다.
async def get_current_doctor(request: Request, db: Session = Depends(get_db)):
credentials_exception = HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Could not validate credentials",
headers={"WWW-Authenticate": "Bearer"},
)
token = request.cookies.get("access_token")
if not token:
raise HTTPException(status_code=status.HTTP_401_UNAUTHORIZED, detail="Not authenticated")
try:
# this decode will check expire token, if expired, raise exception
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
print(payload)
username: str = payload.get("sub")
print("get_current_doctor: ", username)
if username is None:
raise credentials_exception
token_data = TokenData(username=username)
except JWTError as e:
print("JWTError", e)
raise credentials_exception
doctor = get_doctor_by_username(username=token_data.username, db = db)[0]
if doctor is None:
raise credentials_exception
return doctor
마지막으로 위처럼 각 http 요청이 들어올 때마다, Middleware로 JWT를 디코딩하고 만약 서명에 문제가 발생시 JWTError를 발생시키는 코드를 통해 JWT를 통한 인증을 구현할 수 있다.
-
nginx의 개요
개요
프론트 엔드 뷰어와, 백엔드 서버를 결합하는 작업을 수행하면서 CORS 오류로 인한 통신후 Body를 못보는 문제, 분명히 통신과 쿠키는 생성되었는데 쿠키를 읽어드리지 못하는 문제 등, 통신 자체는 성공했는데 웹의 자체적인 보안 및 시스템으로 인해 버그가 자주 발생하였다. 웹에 대한 지식이 없이 이런 버그를 고치는 것은 시행착오가 많을 것 같아, cs-note 섹션에 해당 정보들을 정리하려 한다.
웹에 대하여
초창기 웹은 단순히 URI(Uniform Resource Identifier) 을 통해 클라이언트에 리소스를 보내주고, HTML로 규정된 문서 규칙을 통해 문서끼리, 다른 문서를 쉽게 링크를 통해 가져올 수 있는 구조였다. 하지만 웹서버가 발전하며, 웹 서버는 기존의 서버에서, 클라이언트로 HTML 문서를 보내주는 것을 넘어서, 동적으로 움직이고 디자인이 가능한 문서의 송수신, 자원의 송수신을 넘어선 로직의 실행, 클라이언트와 서버 간의 상태의 저장 등 더욱 다양한 역할을 수행해주게 발전되었다.
해당 문서는 이러한 웹에 발전에 따라, 웹에서 구동되는 제품이 구현되기 위한 백엔드의 구성 요소와 도움이 되는 방법론 등을 정리하는 문서이다.
어떻게 통신할 것인가?
TODO Resource의 송수신
초창기 웹의 주요 역할은 서버에 저장된 리소스(HTML 문서, 이미지·동영상·오디오 같은 미디어 파일, 데이터 파일 등)를 URI를 통해 탐색하고, 이를 클라이언트로 전달하는 것이었다. 이후 웹은 단순한 파일 전송과 링크 연결을 넘어, HTML로 문서를 표현하고, CSS로 시각적 디자인을 더하며, JavaScript로 동적 기능을 구현하는 방향으로 발전하였다. 최근에는 단순한 정적 파일 전송을 넘어, XML·JSON과 같은 데이터 포맷을 송수신하여 브라우저가 직접 HTML을 생성하거나 동적 데이터 처리를 수행한다. 이러한 내용을 정리해보자.
정적 리소스
HTML (문서 구조)
하이퍼링크(URI 기반 파일 연결)
이미지·미디어 파일 전송
문서의 표현력 강화 & 동적 요소
CSS (스타일·디자인)
JavaScript (동적 상호작용)
현대 웹 (데이터 송수신 중심)
XML, JSON (데이터 교환 포맷)
AJAX (비동기 데이터 요청)
TODO 표준화된 데이터 송수신 방식
웹이 단순한 문서 전송을 넘어 다양한 데이터 교환을 필요로 하게 되면서, 서버와 클라이언트 간의 데이터 송수신을 표준화하는 프로토콜이 등장하였다. 이러한 프로토콜은 웹 서비스가 확장될수록 일관성 있는 데이터 접근과 통신 효율성을 보장하는 핵심 역할을 한다.
다룰 내용 예시 : RestAPI, GraphQL, gRPC
클라이언트와 서버의 상태관리
웹이 발전하면서 로그인, 장바구니 같은 기능을 제공하기 위해 서버와 클라이언트는 서로의 상태를 유지할 필요가 생겼다. 이를 위해 상태 관리와 인증 방식이 사용되며, 만약 인증 정보가 유출되면 다른 사용자가 이를 도용해 사칭할 수 있다. 따라서 안전한 인증과 보안 기능이 필수적이다.
인증(Authentication) 대표 기술
세션(Session) + 쿠키(Cookie)
토큰 기반 인증(JWT, OAuth2)
다중 인증(MFA, OTP)
보안(Security) 대표 기술
HTTPS/TLS(데이터 암호화 전송)
CSRF/XSS 방어 기법
세션 하이재킹 방지(만료시간, HttpOnly, Secure 옵션 등)
어떻게 배포환경을 파악할 것인가?
어떻게 WAS를 관리할 것인가?
데이터베이스 최적화
##
참고자료
용어설명
URI
URI(Uniform Resource Identifier)란 인터넷에 있는 자원을 어디에 있는지 자원 자체를 식별하는 방법이다. 우리가 어떠한 자원을 식별할 때는 그 자원이 어디에 있는가? 혹은 그 자원을 뭐라고 하는가? 2가지 방법을 통해 식별을 할 수 있다. 이들이 각각 URL(Uniform Resource Locator)와 URN(Uniform Resource Name)이다.
예시 URI : https://example.com:8080/articles/index.html?search=chatgpt#intro
Type
Context
Schema
https://
Host
example.com
Port
8080
Path
/articles/index.html
Query
?search=chatgpt
Fragment
#intro
우리는 Host + Port + Path를 통해 어떠한 자원이 어느 서버의 어느 위치에 있는지를 알아낼 수 있으며, 이런게 URL이다. 이런 자원이 만약 어디에서 접근하든 고유한 이름으로 구분 가능하면 URN이다. URI는 이 모든 개념을 포함하며, Fragment처럼 자원의 위치만이 아닌 해당 자원 내부를 가르키는 특정 지점에 대한 정보까지도 URI는 포함할 수 있다.
참고링크
웹 개발자가 봐야할 하나의 지도 강의
-
-
상태관리 개요
개요
서버와 클라이언트의 상태관리를 위해서 웹 서버는 인증(Authentication)과 보안(Security)을 고려해야한다. 인증을 통해 사용자가 누구인지, 해당 사용자가 어떠한 권한을 가지고 있는지를 증명할 수 있고, 보안을 통해 이러한 사용자를 인증하는 요소를 다른 사람이 탈취하고나, 사용자의 개인정보를 열람할 수 없도록 보호할 수 있다. 이러한 요소를 구현하는 방법론에 대하여 정리해보자.
Authentication(인증)
왜 인증이 필요한가?
HTTP라는 프로토콜은 무상태(stateless)라는 특징을 갖고 있다.
이 말은 곧, 서버와 클라이언트가 HTTP로 통신할 때 요청 하나하나는 독립적이며, 이전 요청과의 연관성을 HTTP 자체만으로는 알 수 없다는 뜻이다.
예를 들어, 사용자가 어떤 사이트에서 장바구니에 물건을 담았다고 해보자. 그 뒤 다시 장바구니 페이지를 열었을 때, 이전에 담은 상품이 반영되어 있어야 한다. 하지만 HTTP 프로토콜만으로는 “이 사용자가 방금 전에 장바구니에 물건을 담았다”는 사실을 알 길이 없다. 서버는 새로운 요청이 들어올 때마다 단순히 그 순간의 요청 데이터만 보고 응답할 뿐, 누가 어떤 상태를 유지하고 있는지는 구분할 수 없다.
따라서 상태를 유지하기 위해서는 서버가 별도의 장치(세션 저장소, 데이터베이스, 쿠키, 토큰 등)를 활용해 요청과 요청을 연결할 수 있는 수단을 마련해야 한다. 여기서 등장하는 개념이 바로 인증(Authentication)이다.
인증이란 무엇인가?
인증은 말 그대로 서버와 클라이언트가 서로를 식별하는 절차를 의미한다.
즉, 클라이언트가 “나는 누구다”라고 주장할 때, 서버가 그것이 진짜인지 확인할 수 있어야 한다.
사용자가 로그인하면 서버는 그 사용자를 구분할 수 있는 식별자(세션ID, 토큰 등)를 발급한다.
이후 클라이언트는 새로운 요청을 보낼 때마다 이 식별자를 함께 전달한다.
서버는 이를 확인함으로써 “아, 이 요청은 앞에서 로그인한 그 사용자구나” 하고 신원을 이어서 파악할 수 있다.
이 과정을 통해 서버는 단순히 독립된 요청을 처리하는 것을 넘어, 연속된 사용자 경험(로그인 유지, 장바구니 상태 반영, 권한 확인 등)을 제공할 수 있게 된다.
인증된 상태를 유지하는 수단
보통 인증은 로그인, MFA, OTP, 하드웨어 토큰 등 강력하지만 복잡한 알고리즘을 사용하기에 무거운 1차적인 인증과, 아래의 나열한 한번 인증된 상태를 유지하여 HTTP 통신에 대한 인증된 상태를 유지하는 인증이 있다. 해당 포스트는 상태 유지와 관련된 인증에 대해서 소개한다.
Cookie
쿠키란 서버가 브라우저에 사용자에 대한 정보를 넣을 수 있는 수단으로, 응답을 보낼 때 쿠키를 설정하면 브라우저는 이를 저장하고 앞으로 해당 서버와 통신을 수행할 때 항상 쿠키를 같이 붙여서 보낸다. 서버와 클라이언트의 상태관리를 브라우저가 서버별로 저장하는 것이다.
Token TODO
토큰이란 문자열로 서버가 사용자를 인증하기 위해 특정 문자열을 통해 사용자를 인증하는 방식을 말한다. 브라우저가 존재하지 않는 Android나 IOS 등은 쿠키를 사용할 수 없기에 이러한 토큰을 통해 인증을 수행한다.
Session TODO
세션은 서버가 세션 DB라는 별도의 데이터베이스를 생성하여, 브라우저에 쿠키 등을 통해 세션 ID를 저장하게 해 접속을 수행하게 하는 방법으로 서버가 각 사용자에 대한 모든 인증 정보를 세션 DB에 저장하기에 모든 리퀘스트가 들어올 때마다 탐색하는 자원이 필요하지만 유저의 접속을 종료시키는 등의 추가적인 기능을 개발할 수 있게 해준다.
JWT
세션의 탐색 비용 및 추가적인 DB의 필요성이라는 단점을 해결하기 위한 방법론으로, 유저의 ID를 기반으로 서버가 Sign을 수행하여 JWT라는 토큰을 생성하여 유저에게 넘겨주고, 유저가 JWT를 기반으로 인증을 수행하는 방법이다. 서버가 해야할 일을 토큰의 유효성만 판단하면 되기에 비용이 값싸지만 유저의 계정 접속 종료등 유저를 관리하기 위한 구분을 수행할 수 없기에 추가적인 기능의 개발은 힘들다. (Redis 등의 세션 DB를 위한 값싼 DB를 사용)
Security(보안)
CORS
브라우저는 Origin이 다른 출처에 대한 접근을 원칙적으로 차단한다. 이러한 정책으로 인해 실제 서버를 구성할 때 오류가 나는 경우가 많은데, 이러한 CORS Error의 CORS에 대해서 자세하게 알아보자.
HTTPS
SSL 인증서
웹에 대하여
-
CORS
Cross Origin Resource Sharing(CORS)
우리가 API요청을 보내다보면 자주 CORS Error라는 표현을 들어볼 수 있다. 각종 통신을 수행할 때 오류를 쉽게 걸리게 하는 머리가 아픈 녀석이다. 그렇다면 브라우저는 왜 이런 정책을 사용하고 우린 어떻게 이런 Error를 해결할 수 있을까?
SOP 정책
SOP란?
사실 실제 오류가 걸리게하는 정책은 CORS라 불리는 것이 아닌 SOP(Same Origin Policy)이다. 브라우저는 기본적으로 Origin이 다른 곳에 요청을 보낼 때 해당 요청을 차단하는 정책을 기본값으로 가지고 있다. 그렇다면 여기서 Origin이 정확히 무엇일까?
http://front.com:80/pages/10?search=good 이런 URL이 있다고 가정해자
프로토콜은 http
host주소는 front.com
포트 번호는 80
이 3가지 요소를 합쳐져서 Origin이라고 불린다.
기본적으로 브라우저는 우리가 이런 Origin이 다른 곳에 요청을 보낼 때 요청을 차단을 수행하지만, 실제 우리가 사용하는 환경은 다른 출처에 요청을 보내야하는 경우가 존재하기에, 이러한 정책을 통과시켜주는 방법론이 CORS이다. 즉 브라우저는 너가 다른 Origin으로 요청을 보내고 싶으면 CORS를 통해 허용을 하라고 표현해주는 것이다.
왜 SOP가 필요할까?
아래와 같은 시나리오를 생각해보자.
무수한 CORS 오류를 겪은 철수는 이 에러에 진절머리가나 SOP 정책을 없애리도록, 자신이 만든 사이트에
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
처럼 허용을 해버렸다.
영희는 철수에 사이트를 가입하고, 플래시 게임을 하려 evil.com에 접속을 한다. 그런데 evil.com 관리자는 철수의 동료라 SOP를 무시하는 코드를 실행시켰다는 것을 알아 아래와 같은 코드를 넣어두었다.
<script>
fetch('http://철수.com').then(/**/) // 이후 공격자에게 전송
</script>
영희의 브라우저는 요청을 받았을 때, Source와 fetch의 요청되는 사이트의 Origin이 다르다는 사실을 확인했지만, 철수의 사이트는 어떤 사이트가 출처든 허용되는 설정을 해버렸다.
공격자는 영희가 evil.com에 접속했을 때 철수의 사이트에 화면을 그대로 볼 수 있게 되버렸고, 영희의 해당 사이트의 개인정보가 탈취되었다…
즉 SOP 정책을 통해서 Origin이 다른 사이트의 fetch를 브라우저가 자체적으로 차단함으로써, 해당 사이트의 정보를 다른 사이트가 탈취할 수 없도록 만드는 것이 해당 정책이 있는 이유이다. 즉 사용자가 악성 사이트에 들어가더라도, 다른 사이트의 정보, 토큰, 세션 ID 등이 탈취되지 않도록 보호하는 정책이다.
CORS
CORS란?
현대 웹에서는 특정 사이트가 다른 사이트의 데이터를 활용해야 하는 경우가 많다. 예를 들어, 프론트엔드에서 자체 백엔드 서버로 요청을 보내거나, 공공 데이터 포털처럼 외부에서 제공하는 API에 접근하는 경우가 있다. 하지만 이러한 요청은 대체로 서로 다른 Origin을 가지므로, 브라우저의 SOP 정책에 의해 기본적으로 차단된다.
이를 해결하기 위해 등장한 것이 CORS(Cross-Origin Resource Sharing) 정책이다.
예를 들어, 프론트엔드에서 fetch 명령으로 어떤 백엔드 서버에 데이터를 요청한다고 하자. 이때 프론트엔드의 URL과 백엔드 서버의 URL이 서로 다른 Origin을 가지면, 브라우저는 SOP 규칙에 따라 해당 요청을 차단한다.
그러나 만약 백엔드 서버가 CORS 설정을 통해 프론트엔드 서버의 Origin을 허용한다면, 브라우저는 이 요청을 정상적으로 실행할 수 있다. 그 결과, 사용자는 브라우저를 통해 해당 백엔드 서버의 데이터에 접근할 수 있게 된다.
즉, CORS라는 것은 미리 특정 사이트에 대한 사용자가 접근할 수 있는 페이지나, 정보를 다른 사이트가 봐도 된다고 허용을 해주는 것이다. 또한 이런 허용은 브라우저에서 설정하는 것이 아닌 특정 사이트(즉 백엔드 서버나, API 서버 등등)에서 허용을 해주는 것이다.
CORS의 세가지 시나리오
JavaScript, Browser, API Server의 통신은 위와 같은 그림으로 나타낼 수 있다. 여기서 빨간 부분이 CORS의 시나리오에 해당하는 부분이다. 각 동작에 따라 CORS는 크게 3가지의 시나리오로 나누어서 판단을 수행한다.
Simple Request
Simple Request는 Get과 Post 같은 요청을 보낼 때 수행되며, 요청을 보내는 걸 별도의 인증 없이 바로 수행할 수 있으며, 만약 인증이 수행되지 않더라도 응답에 대한 데이터를 JavaScript가 못받는 것 뿐이다. 해당 요청은 Access-Control-Allow-Origin에 Origin이 포함만 되어있다면, 별도의 요청없이 바로 수행된다.
Preflight Request
HTTPS의 특별한 메소드인 Option 메소드를 활용하며 예비 요청을 사전에 보낸다. 이 예비 요청의 역할은 Origin과 Access-Control-Allow-Origin을 비교해주어 Origin이 CORS에 등록되어있으면 200을 보내는 역할이다. 그 후 해당 요청을 통과하면 본 요청을 보내주는 역할이다. 대부분의 요청은 Preflight Request로 검증을 수행한다.
CORS가 생기기 이전 SOP만 가능하다는 가정하에 만들어진 서버들이 CORS 처리 매커니즘이 있는지 확인해주기 위해 Preflight Request를 통해 브라우저가 사전에 확인을 해줌으로써, 해당 사항을 처리할 수 있는 서버만 해당 동작이 수행될 수 있도록 만든 것이다.
Credentitaled Request
Cookie나 Session에 대한 정보가 담긴 HTTPS 요청이 들어올 때 Credentitaled Request가 수행된다. 기본적인 매커니즘은 Origin을 검사하는 Preflight Request와 동일하지만, 해당 Request를 수행할 때 Access-Control-Allow-Origin이 Wild Card : * 로 설정되어있을 때 브라우저가 자동으로 차단하며, Access-Control-Allow-Credentials가 true일 때만 해당 요청을 수락하는 추가적인 보안 사항이 존재한다.
CORS와 개발환경
CORS는 기본적으로 Origin이 사전에 허용되어있거나, 동일해야지만 브라우저가 fetch를 허용해준다. 하지만 여기서 문제가 발생한다. 개발환경인 경우 모든 개발자의 컴퓨터를 어딘가에 배포한 것이 아닌 각자 컴퓨터에서 프론트엔드를 실행하기에 Origin을 하나로 고정할 수 없다는 문제가 발생한다.
또한 리다이렉트 등의 문제가 발생하면, 기존의 허용해두었던 Origin이 변경되어 무수한 CORS 에러를 만나게 되었다.
근본적인 문제는 각 개발환경은 ip가 모두 다른 것이다. 그렇기에 FE 개발환경과 백엔드 서버를 CORS 오류가 없이 연결하기 위해서는, localhost:3000과 같은 특정 도메인을 프론트엔드 개발환경에서 만드는 브라우저가 인식하는 Origin을 모든 개발환경의 개발자들이 통일할 필요성이 있고, 통일한 Origin을 백엔드에서 allow origin으로 허용해주어야 SOP 정책을 통과할 수 있다.
프론트엔드와 백엔드를 연결하는 과정에서 인증과 CORS 정책이 겹쳐 해결한 방식을 아래에 포스트에 정리하였다.
```
-
Web의 개요
개요
프론트 엔드 뷰어와, 백엔드 서버를 결합하는 작업을 수행하면서 CORS 오류로 인한 통신후 Body를 못보는 문제, 분명히 통신과 쿠키는 생성되었는데 쿠키를 읽어드리지 못하는 문제 등, 통신 자체는 성공했는데 웹의 자체적인 보안 및 시스템으로 인해 버그가 자주 발생하였다. 웹에 대한 지식이 없이 이런 버그를 고치는 것은 시행착오가 많을 것 같아, cs-note 섹션에 해당 정보들을 정리하려 한다.
웹에 대하여
초창기 웹은 단순히 URI(Uniform Resource Identifier) 을 통해 클라이언트에 리소스를 보내주고, HTML로 규정된 문서 규칙을 통해 문서끼리, 다른 문서를 쉽게 링크를 통해 가져올 수 있는 구조였다. 하지만 웹서버가 발전하며, 웹 서버는 기존의 서버에서, 클라이언트로 HTML 문서를 보내주는 것을 넘어서, 동적으로 움직이고 디자인이 가능한 문서의 송수신, 자원의 송수신을 넘어선 로직의 실행, 클라이언트와 서버 간의 상태의 저장 등 더욱 다양한 역할을 수행해주게 발전되었다.
해당 문서는 이러한 웹에 발전에 따라, 웹에서 구동되는 제품이 구현되기 위한 백엔드의 구성 요소와 도움이 되는 방법론 등을 정리하는 문서이다.
어떻게 통신할 것인가?
TODO Resource의 송수신
초창기 웹의 주요 역할은 서버에 저장된 리소스(HTML 문서, 이미지·동영상·오디오 같은 미디어 파일, 데이터 파일 등)를 URI를 통해 탐색하고, 이를 클라이언트로 전달하는 것이었다. 이후 웹은 단순한 파일 전송과 링크 연결을 넘어, HTML로 문서를 표현하고, CSS로 시각적 디자인을 더하며, JavaScript로 동적 기능을 구현하는 방향으로 발전하였다. 최근에는 단순한 정적 파일 전송을 넘어, XML·JSON과 같은 데이터 포맷을 송수신하여 브라우저가 직접 HTML을 생성하거나 동적 데이터 처리를 수행한다. 이러한 내용을 정리해보자.
정적 리소스
HTML (문서 구조)
하이퍼링크(URI 기반 파일 연결)
이미지·미디어 파일 전송
문서의 표현력 강화 & 동적 요소
CSS (스타일·디자인)
JavaScript (동적 상호작용)
현대 웹 (데이터 송수신 중심)
XML, JSON (데이터 교환 포맷)
AJAX (비동기 데이터 요청)
TODO 표준화된 데이터 송수신 방식
웹이 단순한 문서 전송을 넘어 다양한 데이터 교환을 필요로 하게 되면서, 서버와 클라이언트 간의 데이터 송수신을 표준화하는 프로토콜이 등장하였다. 이러한 프로토콜은 웹 서비스가 확장될수록 일관성 있는 데이터 접근과 통신 효율성을 보장하는 핵심 역할을 한다.
다룰 내용 예시 : RestAPI, GraphQL, gRPC
클라이언트와 서버의 상태관리
웹이 발전하면서 로그인, 장바구니 같은 기능을 제공하기 위해 서버와 클라이언트는 서로의 상태를 유지할 필요가 생겼다. 이를 위해 상태 관리와 인증 방식이 사용되며, 만약 인증 정보가 유출되면 다른 사용자가 이를 도용해 사칭할 수 있다. 따라서 안전한 인증과 보안 기능이 필수적이다.
인증(Authentication) 대표 기술
세션(Session) + 쿠키(Cookie)
토큰 기반 인증(JWT, OAuth2)
다중 인증(MFA, OTP)
보안(Security) 대표 기술
HTTPS/TLS(데이터 암호화 전송)
CSRF/XSS 방어 기법
세션 하이재킹 방지(만료시간, HttpOnly, Secure 옵션 등)
어떻게 배포환경을 파악할 것인가?
어떻게 WAS를 관리할 것인가?
데이터베이스 최적화
##
참고자료
용어설명
URI
URI(Uniform Resource Identifier)란 인터넷에 있는 자원을 어디에 있는지 자원 자체를 식별하는 방법이다. 우리가 어떠한 자원을 식별할 때는 그 자원이 어디에 있는가? 혹은 그 자원을 뭐라고 하는가? 2가지 방법을 통해 식별을 할 수 있다. 이들이 각각 URL(Uniform Resource Locator)와 URN(Uniform Resource Name)이다.
예시 URI : https://example.com:8080/articles/index.html?search=chatgpt#intro
Type
Context
Schema
https://
Host
example.com
Port
8080
Path
/articles/index.html
Query
?search=chatgpt
Fragment
#intro
우리는 Host + Port + Path를 통해 어떠한 자원이 어느 서버의 어느 위치에 있는지를 알아낼 수 있으며, 이런게 URL이다. 이런 자원이 만약 어디에서 접근하든 고유한 이름으로 구분 가능하면 URN이다. URI는 이 모든 개념을 포함하며, Fragment처럼 자원의 위치만이 아닌 해당 자원 내부를 가르키는 특정 지점에 대한 정보까지도 URI는 포함할 수 있다.
참고링크
웹 개발자가 봐야할 하나의 지도 강의
-
-
-
Git의 object와 refs 저장방식
Git의 저장방식
git으로 프로젝트를 진행하다보면, .git이라는 숨김폴더가 생성되는 것을 볼 수 있다. 이러한 .git 폴더 안에는 프로젝트 작업을 수행하면서 commit add 등 명령어를 통해 수행한 작업들의 결과들이 생성되는데 이번 포스트에서 해당 정보에 대한 저장방식, 그 중에서도 git의 objects와 refs에 저장되는 정보에 대해 알아보자.
Git objects
위의 그림에서 git이 실제로 어떻게 저장되느냐에 대한 설명이 잘 나와있다.
우리가 working directory의 작업을 commit을 수행하면,
해당 파일들과 디렉토리들은 Blob과 Tree라는 구조로 .git/objects에 저장된다.
commit 객체가 생성되어 해당하는 커밋에 프로젝트 폴더를 가르키는 Tree 객체를 가르킨다. 또한 해당 커밋 이전의 부모 커밋 또한 가르킨다.
commit object를 Head 포인터가 가르킨다.
자 전체적인 구조는 위와 같이 수행되지만, 하나하나가 잘 이해되지 않는다. 그러니 자세히 파악해보자.
git objects 파일을 자세히 볼 땐
git cat-file -p 파일의 hash코드
명령을 통해 해당 오브젝트 파일을 자세히 살펴볼 수 있다.
이 글을 포스트하는 github 블로그 역시도 git으로 관리되고 있다. 그러면 한번 예시를 살펴봐볼까?
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ ls
0a/ 1b/ 34/ 4c/ 67/ 7e/ 8f/ a2/ b5/ c1/ ca/ e8/ fb/
0f/ 24/ 36/ 50/ 68/ 80/ 92/ a9/ b8/ c2/ d2/ ea/ fc/
13/ 25/ 38/ 51/ 76/ 85/ 9a/ ae/ ba/ c4/ d3/ ee/ fd/
19/ 2f/ 3e/ 60/ 7a/ 86/ 9e/ b0/ bc/ c5/ d5/ f3/ info/
1a/ 30/ 44/ 62/ 7d/ 8b/ 9f/ b2/ bd/ c7/ db/ f9/ pack/
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ ls 1b/
2948a17f027fd4f4359c53a60b9582a3b1c265
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git cat-file -p 1b2948a17f027fd4f4359c53a60b9582a3b1c265
040000 tree 7a6a6a64b2bbae6b6cec73624b610e31830b56ac Projects
040000 tree 51fb9a02110fa88741738be230342544256e1f73 Tutorial
040000 tree 7a5657ae0999f622f6509b8416f659a0262eba33 cs-note
040000 tree c472bd9693f8ca55e7590d9ace65ee51b6f99179 dev-log
100644 blob a49ba48448f906d814cc83e50fc18f81cae53844 index.md
040000 tree b56fcfa45f3a0afaf2c480470f2b38f1b44fc26d tech-review
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git cat-file -p a49ba48448f906d814cc83e50fc18f81cae53844
---
---
자 이러한 결과가 나왔다. 그러면 이 결과를 한번 자세히 분석해보자!
Git Blob
먼저 git이 파일 버전 관리를 할 때 핵심이 되는 저장방식인 Blob(Binary Large Object)에 대해서 알아보자.
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git cat-file -p a49ba48448f906d814cc83e50fc18f81cae53844
---
---
자 Blob파일을 우리가 열어보았을 때 해당 파일인 index.md의 실제 저장된 값과 정확히 일치하는 결과를 확인할 수 있다.
그렇다면 파일이 수정되었을 때 Blob은 어떻게 저장할까?
# Blob 1
첫 번째 파일
# Blob 2
첫 번째 파일
두 번째 파일
파일이 위와 같이 수정되었을 때 Blob은 각 파일의 전체 내용을 기반으로 Hash함수를 통과시켜 40글자에 해당하는 문자열을 파일이름으로 사용한다. 이때 앞선 2글자는 폴더로, 뒤의 38글자는 파일이름으로 사용된다.
처음 objects의 폴더에 나온 수많은 2글자들은 이런 식으로 생성된 hash의 결과값들이다. git에서 각 오브젝트들은 이러한 hash값을 기반으로 접근할 수 있다.
각 파일이 조금의 수정이라도 일어난다면 git은 새로운 Blob파일로 저장하며, 수정이 일어나지 않았을 시 동일한 Blob파일로 저장된다.
이러한 구조의 장점은 무엇일까?
바로 hash함수의 특징인 같은 값을 통과시킬 땐 같은 결과가 나온다는 것이 핵심이다.
git은 버전관리 프로그램이다. 커밋을 수행할 때마다 파일의 버전을 기록해야하고 변화를 추적할 수 있어야한다. 하지만 우리가 git을 사용할 때 항상 모든 파일들이 커밋을 수행할 때마다 바뀌는가?
아니다. 대부분의 파일들은 이전버전과 변하지 않는 경우가 많으며 수십 번의 커밋 후에도 바뀌지 않을 수도 있다. 이때 Blob의 저장방식이 강점을 발휘한다. Blob은 파일 내용을 기반으로 hash를 생성해 파일이름을 생성한다. 즉 어떤 컴퓨터에서든 어떤 파일로 저장되었든 어느 시점에 저장하든, 파일 내용이 동일하다면 동일한 Blob으로 저장된다.
이러한 방식은 git이 버전관리를 수행하면서도 저장 공간을 효율적으로 사용하게 해준다. 각 커밋을 수행할 때 시점별로 commit 오브젝트는 tree오브젝트를 가르키고 각 tree 오브젝트는 Blob을 가르키는데, 이때 동일한 내용은 여러 커밋 시점에서 하나의 Blob만을 가르키게 저장할 수 있다.
여기서 또 하나의 용량을 감소하는 트릭이 존재한다.
git 저장구조, wikipedia
Blob 파일의 생성 원리를 보면 파일 전체를 스냅샷처럼 저장해 전체 파일 내용을 기반으로 hash를 생성한다. 하지만 이런 말을 들어보았을 것이다. git은 파일의 수정된 내역만 저장하여 효율적이게 디스크 공간을 활용한다.
실제로 git은 델타압축이라는 파일의 수정된 내역만을 저장하여 공간을 절약시켜, 각각의 Blob을 이전 버전에서의 수정 내역만을 기반으로 생성시키고 checkout 등으로 특정 버전을 불러와야할 때 이러한 수정 내역을 일괄적으로 읽어 해당 버전을 복구한다. 그렇기에 전체 내용을 저장하는 것도 수정된 내역만 저장하는 것도 맞는 말이다.
Git Tree
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ ls 1b/
2948a17f027fd4f4359c53a60b9582a3b1c265
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git cat-file -p 1b2948a17f027fd4f4359c53a60b9582a3b1c265
040000 tree 7a6a6a64b2bbae6b6cec73624b610e31830b56ac Projects
040000 tree 51fb9a02110fa88741738be230342544256e1f73 Tutorial
040000 tree 7a5657ae0999f622f6509b8416f659a0262eba33 cs-note
040000 tree c472bd9693f8ca55e7590d9ace65ee51b6f99179 dev-log
100644 blob a49ba48448f906d814cc83e50fc18f81cae53844 index.md
040000 tree b56fcfa45f3a0afaf2c480470f2b38f1b44fc26d tech-review
이번엔 Tree 오브젝트를 살펴보자, 위의 그림을 보듯이 tree object는 자신이 가지고 있는 Tree와 Blob을 가르키는 오브젝트이다.
트리는 각 ‘디렉토리’별로 ‘파일 이름’을 저장한다.
현재 블로그에서 디렉토리를 담당하는 cs-note, dev-log 등은 tree로 저장되고ㅡ, index.md같은 실제 파일은 Blob으로 저장된 모습을 볼 수 있다.
또한 이러한 Tree 역시도 Blob과 마찬가지고 hash코드로 파일명이 지정된 것을 볼 수 있다.
Blob과 달리 Tree는 디렉토리 전체를 기반으로 hash값을 생성하기에, 포함된 일부 파일이 하나만 수정되더라도 Tree 역시도 새로운 Tree 객체로 생성된다.
하지만 이를 통해 git은 파일의 내용만 저장하는 Blob과 달리 파일의 이름, 실행권한, 디렉토리 구조 등을 Tree 객체를 통해 저장할 수 있다.
여기서 .git/index 파일을 한번 살펴보자.
$ git ls-files --stage | tail
100644 d344d060ac0c5db0f9bb01c4f1ce7e0d156598b9 0 search.html
100644 f259c5a08dd5d121a34a000017cd197ea02dc90b 0 sitemap.xml
100755 764df0355bdab53e2362b2f821e6c649162694d5 0 start.sh
100644 c9712bd9af8e82846391e82f7c50077b095f87fc 0 tag.html
100755 bdfb10641d93f265a382b3014341a15c68e4b139 0 tool/find-orphan-post-img.sh
100755 537c62c2bb5465d7594f085f8cf4935cf07ac4c4 0 tool/fix-image-references.sh
100755 01433e92888c8ce58bb79792ef786aa58d1acfc9 0 tool/pre-commit
100755 95b19d9863b6ad564bf6208f719a2bcc657a9ffc 0 tool/save-images.sh
100755 e36c4a696d2e351dc0efcd40db81d87e7ef1fb11 0 tool/to-skeleton.sh
100644 50fe65a76cb17611bb041bd5d2cc517ec863323f 0 utterances.json
git index 자료 출처
해당 파일의 컬럼은 각각 staging area로 옮겨진 파일들에 대한 나열을 수행하며, 각 staged 파일들에 대해
[mode] : 파일의 타입과 권한을 의미
[object] : 해당 파일을 나타내는 .git 내부 hash값
[stage] : 기본값 0 충돌이 났을 때 충돌난 각 파일 그룹들을 구분해주는 키
[file] : 실제 파일 경로
를 의미한다.
tree는 확실하게 commit된 디렉토리(Tree)와 Blob들을 기록하지만, Staging 공간은 오로지 add된 파일들을 Blob으로 생성하고 이들을 나열하는 차이를 확인할 수 있다.
하지만 만약 현재 staing 공간에 존재하는 파일들을 tree로 만들고 싶다면, git write-tree 명령을 통해 Tree객체를 생성해주고, 이에 대한 hash 값을 커맨드에 출력해준다.
Git Commit
프로젝트의 디렉토리에 대한 정보와 파일 내용에 대한 정보를 Tree와 Blob을 통해 저장하였다.
하지만 이는 한 시점에 프로젝트의 상태를 기록하는 방법론일 뿐이다.
git은 우리가 commit을 수행할 때마다 해당 시점에 누가 기록했는지, 이 이전 시점의 기록은 무엇인지 추적이 가능해야한다. 이러한 역할을 수행해주는 것이 commit 객체이다.
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git log
commit f342a499d9ea17b2956f9bea91c33354d1870984 (HEAD -> main, origin/main, origin/HEAD)
Author: SeongWooJo <abc8325767@gmail.com>
Date: Wed Aug 13 22:35:28 2025 +0900
search
commit 1a733fefb50c137ab2b95285b82f084dc60193aa
Author: SeongWooJo <abc8325767@gmail.com>
Date: Wed Aug 13 22:29:42 2025 +0900
Update _config.yml
commit 80646a438cff8f50884f6bf2945b2f4e15887ff4
Author: SeongWooJo <abc8325767@gmail.com>
Date: Wed Aug 13 22:23:09 2025 +0900
.
commit 19781c03fd83f4c185f9ab5051c8bba72983bace
Author: SeongWooJo <abc8325767@gmail.com>
Date: Wed Aug 13 22:22:41 2025 +0900
우리가 git log 명령을 수행하면 위와 같이 hash값과 함께 각 커밋에 대한 정보를 나열해주는 것을 볼 수 있다. 어떻게 이런 작업이 가능한 것일까?
아까처럼 hash 코드를 기반으로 파일을 열어보자.
abc83@develop MINGW64 ~/development/SeongWooJo.github.io/.git/objects (GIT_DIR!)
$ git cat-file -p 19781c03fd83f4c185f9ab5051c8bba72983bace
tree ba3c9fe46ea8e11d47e739b69c347cf1d5efd75e
parent dba0935cb5910000496ffac60c49ba2534de4001
author SeongWooJo <abc8325767@gmail.com> 1755091361 +0900
committer SeongWooJo <abc8325767@gmail.com> 1755091361 +0900
robot
해당 커밋은 git blog를 배포하기 위해 robot.txt를 시험하던 시점의 커밋이다. commit 메세지로 robot으로 간단하게 적었다.
이 객체를 분석해보자.
tree : 해당 커밋 시점의 프로젝트 전체를 가르키는 tree 객체의 hash값이다.
parent : 해당 커밋의 이전 커밋 객체를 가르키는 hash값이다.
author : 해당 커밋 시점의 코드를 작성한 사람에 대한 정보이다.
committer : 해당 커밋을 작성한 사람에 대한 정보이다.
“robot” 해당 커밋을 작성할 때 메세지이다.
이처럼 버전관리를 위해 필요한 추적을 위한 정보들이 커밋 객체에 담긴 것을 확인할 수 있으며, 커밋 객체역시도 tree,blob과 마찬가지로 내용을 기반으로 hash값을 폴더/파일명으로 삼는다.
Git Tag
자 hash를 기반으로 Blob, Tree, Commit의 접근하는 것은 저장도 효율적이고 버전 관리도 될 수 있는 방법이지만, 40글자에 해당하는 hash 코드는 사람이 구분하기에 어렵다.
이를 해결해주기 위한 객체가 바로 Tag 객체이다.
git tag [옵션] <tagname> [<commit>]
git tag -a v1.0 -m "First release"
git tag -s v1.0 -m "Signed release"
git tag v1.1 <commit_hash>
우리는 위와 같은 명령을 통해 각 hash 코드에 사람이 접근하기 좋은 이름을 붙여줄 수 있다.
이를 기반으로 기존에는 git checkout hash코드 처럼 40글자의 hash코드를 사용해야하는 명령에서, git checkout 태그명으로 미리 지정한 tagname을 기반으로 hash코드를 대체할 수 있다.
다만 위의 예시처럼 우리가 어떻게 태그를 생성했느냐에 따라 구현방식이 조금씩 다르다.
-a 옵션
$ git cat-file -p c3d5f2a
object 7a9b74c6b6f4d4c85b8e4cf59ef1fa3e63c5c3ad
type commit
tag v1.0
tagger Alice <alice@example.com> 1713250000 +0900
First release
-a 옵션을 사용했을 때는 해당 hash 파일에 대한 태그를 생성할 때 누가 태그를 붙였는지, 해당 태그를 붙일 떄 시점 및 메세지를 같이 남긴다.
-s 옵션
object 7a9b74c6b6f4d4c85b8e4cf59ef1fa3e63c5c3ad
type commit
tag v1.0
tagger Alice <alice@example.com> 1713250000 +0900
Signed release
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2
iQEzBAABCAAdFiEE...
-----END PGP SIGNATURE-----
-s 옵션은 -a 옵션에 더해 해당 tagger를 검증할 수 있는 키를 남겨, public key를 통해 검증할 수 있게 한다.
그냥 만들시
이때는 tag 객체가 생성되는 것이 아닌, refs/tags에 해당 태그가 가르키는 hash코드에 대한 정보만이 한 줄로 기록된다.
git refs
.git/refs 폴더에는 이러한 객체를 가르키는 포인터를 만들 수 있으며 이곳에 저장되는 포인터 정보는
.git/refs/heads
각 브랜치별 최신 작업 커밋을 가르키는 hash값 및 working directory가 작업하고 있는 버전의 commit hash값
.git/refs/tags
사전에 태그로 등록한 commit, tree, blob hash값이 저장되는 장소
.git/refs/remotes
local 저장소가 아닌 remote 저장소에 브랜치들에 대한 최신 commit hash값이 저장되는 장소
와 같이 앞서 공부한 git의 객체들에 대한 hash값을 refs 폴더에서 실제 git에서 작업되는 hash값을 관리해줌으로써 우리가 브랜치명, 원격 브랜치명, 태그명으로 실제 hash값을 사용하지 않고 쉽게 이동할 수 있다.
참고자료
git의 저장방식 영상
git blob, tree, commit
git tags
git에 대한 추후 볼 내용1
-
Git 정리
Git
개요
백엔드 시스템을 개발하면서, 기존의 연구 개발과는 달리 여러 사람이 병렬로 작업을 수행하게 되었다. 이에 따라 Git을 사용하게 되었고, 버전 및 브랜치 관리를 철저히 해야 할 필요성을 절실히 느꼈다. 이에 따라 Git에 대해 정리할 필요성을 느꼈고, 그 첫 번째로 Git의 공간과 파일의 상태에 대해 기초적인 내용을 정리한다.
Git이란?
Git이란 Version Control System의 일종으로, 소프트웨어 개발 및 협업 프로젝트에서 소스 코드, 문서, 기타 파일의 변경 사항을 추적하고 관리하는 데 사용된다.
혼자 작업하든 팀으로 작업하든, 버전 관리를 도입하면 다음과 같은 장점이 있다:
파일과 프로젝트를 이전 상태로 쉽게 되돌릴 수 있다.
누가 언제 어떤 작업을 했는지 추적할 수 있으며, 문제 발생 시 관련 이력을 확인할 수 있다.
파일을 잃어버리거나 실수로 수정했을 때 쉽게 복구할 수 있다.
서로의 작업을 덮어쓰지 않고 병렬로 작업하며, 변경 사항을 손쉽게 병합할 수 있다.
버전 관리 시스템(VCS)은 Git 외에도 다양한 도구들이 존재한다. 예를 들어 GUI 기반의 간편함을 선호하는 개발자들은 Mercurial을 사용하기도 하고, 코드 외의 리소스까지 통합 관리하는 Perforce (P4V) 도 있다. 하지만 현재까지 가장 널리 사용되는 VCS는 단연 Git이다.
Git의 공간
Git은 파일들의 변경 이력을 추적하여 버전을 관리하는 도구다.
그렇다면 파일을 수정할 때마다 Git이 모든 변화를 자동으로 기록하는 것일까?
→ 그렇지 않다.
Git은 우리가 작업하는 디렉토리의 파일 상태를 추적하고, 특정 명령을 실행할 때마다 스냅샷처럼 그 시점의 파일 상태를 기록한다(그러나 저장 방식은 파일을 복제하는 것이 아닌 변화를 기록하는 차이가 존재한다). 이러한 과정에서 Git은 변경된 파일들을 다양한 단계에서 관리한다. Git이 추적하는 파일 상태는 아래와 같은 네 가지 주요 공간을 통해 이해할 수 있다:
1. Working Directory
Git으로 관리하기 위해 git init 등을 실행한 후 작업하게 되는 실제 디렉토리다.
이곳은 개발자가 직접 파일을 수정하거나 저장하는 공간이며, Git이 자동으로 버전을 기록하지 않는다.
즉, 파일을 수정하거나 새로 생성해도 git add 또는 git commit 명령을 실행하지 않으면, Git이 버전 이력에는 반영하지 않는다.
2. Staging Area
Staging Area는 로컬 저장소에 기록(commit) 하기 전에 Git이 변경 내용을 임시로 저장하는 공간이다. 해당 공간이 존재함으로써 Merge 등의 작업을 수행할 때 충돌을 해결하거나, 한번에 커밋에 어떠한 정보들만 업데이트할지 천천히 파일들을 추가할 수 있다. 메모리 등에 임시로 저장되는게 아닌 별도의 공간에 존재하기에 이런 작업들을 오래 수행할 수 있다.
git add 명령을 사용하면, 해당 파일은 Staging Area에 추가된다.
Staging Area를 사용하면 원하는 변경 사항만 선택적으로 커밋할 수 있어, 커밋의 목적과 단위를 깔끔하게 분리할 수 있다.
3. Local Repo
git commit 명령을 실행하면, Staging Area에 있던 변경 내용이 로컬 저장소에 커밋된다. 이 저장소는 .git 폴더 내부에 존재하며, 모든 커밋 이력, 브랜치 정보, 메타데이터 등을 포함한다. Git은 이곳에 실제 파일 내용뿐 아니라, 이전 버전과의 차이점, 커밋 메시지, 작성 시간, 작성자 등의 정보를 구조화하여 저장한다.
구체적인 .git 폴더의 저장 방식에 대해서는 링크를 참조하자 : 저장방법 로직
4. Remote Repo
로컬 저장소의 커밋 내역을 다른 사람과 공유하려면, git push 명령을 사용하여 Remote Repository로 전송한다.
Remote Repository는 GitHub, GitLab, Bitbucket 등의 원격 저장소이며, .git 폴더와 동일한 커밋 이력을 저장하고 관리한다.
원격 저장소를 통해 팀원 간의 협업이 가능해지며, pull, fetch, merge 등을 통해 변경 사항을 주고받을 수 있다.
Git의 파일의 상태
Git은 결국 각 파일이 시간에 따라 어떻게 변화해왔는지를 기록하는 도구이다. 이에 따라 각 공간으로 이동하는 것에 더해 Git은 사용자가 명시적으로 실행하는 명령에 따라 각 파일의 상태(state)를 구분하고 관리한다.
Git에서 파일이 가질 수 있는 상태는 다음과 같다:
Untracked / Tracked → (Unmodified, Modified, Staged)
1. Untracked
Git은 파일의 변경 이력을 추적하고 버전을 관리하지만, 한 번도 Git에 추가되지 않은 파일은 Git 입장에서 “변경”이 아닌 “새로운 파일” 일 뿐이다.
즉, Git이 한 번도 기록한 적이 없는 파일은 과거 상태가 없기 때문에 변경 이력을 추적할 수 없다. 이러한 상태를 Untracked 이다.
실제 Git에선 git 프로젝트 내에서 새로운 파일을 생성시켰을 때, 기존의 추적되던 파일을 삭제하였을 때,
또한, .gitignore에 등록된 파일들도 일부러 추적하지 않기 때문에 Untracked 상태로 간주된다.
이는 예를 들어 다음과 같은 경우 유용하다:
대용량 파일로 인해 Git 저장소에 포함시키고 싶지 않은 경우
민감 정보(예: API 키, 비밀번호)가 포함된 파일을 외부 저장소에 업로드하고 싶지 않은 경우
위의 상태 도식과 달리 Tracked 상태의 파일을 삭제하지 않으면서 Untracked로 만들고 싶을 수 있다. 그런 경우 위처럼 git add, unstaged 같은 명령으론 수행할 수 없고 git rm --cached example.txt 라는 명령처럼 실수로 추적한 파일을 local repo와 staging area에서 없앨 수 있다.
2. Staged
위의 공간 설명에서 Staging Area란 공간은 commit을 수행하기 전 기록할 파일의 상태를 임시로 모아두는 공간이다. 이처럼 해당 공간에 파일들이 옮겨졌을 때 해당 파일들은 Staged 상태를 가지게 된다. 만약 Untracked 파일이 Staged 상태가 된다면 그 때부터 추적이 시작되는 것이고, 다시 unstaged하면 Untracked 상태로 돌아간다.
만약 당신이 파일을 Staged 상태로 바꾸고 워크 디렉토리에서 파일을 수정한다면 어떻게 될까?
Staging Area에는 git add 시점의 파일 상태가 기록되는 것이다. 즉, 워킹 디렉토리의 파일과 Staged에 기록된 파일이 다른 것이다.
워킹 디렉토리에서 해당 파일을 수정하면, Git은 "Staging Area 버전" ≠ "Working Directory 버전" 인 것을 인식한다.
3. Unmodified
Commit을 수행하면, Staging Area의 파일 상태가 Local Repository에 기록된다.
이후 git status 같은 명령이 실행될 때마다 Git은 Local Repo(HEAD) 와 워킹 디렉토리를 비교한다.
두 상태가 완전히 동일하다면 해당 파일은 Unmodified 상태이다.
예를 들어, 파일을 Staged 상태로 변경하고, 추가 수정 없이 commit을 하면
commit 직후 그 파일은 Unmodified 상태로 남는다.
4. Modified
위의 상태처럼 Commit 등을 통해 Staged를 Local Repo로 옮긴 후 추가적으로 워킹 디렉토리에서 파일을 수정했을 때, 해당 파일은 Local Repo와 상태가 다른 Modified 상태가 된다.
-
-
프로그래밍의 기본 요소 설명
개요
출처: 쉬운코드 영상
객체와 클래스
객체와 클래스
객체란?
=> 상태가 있고 행동을 하는 실체
클래스란?
=> 객체의 관점에서의 클래스는, 객체가 어떠한 속성이 있고 어떠한 행동을 하는지를 기술한 설계도이다.
// example1
class Car {
private String name;
private double speed;
private Size size;
...
public void start() { ... }
public void stop() { ... }
...
}
Car myCar = new Car("니로");
Car yourCar = new Car("소나타");
Car ourCar = new Car("스포티지");
Class Car는 Car라는 객체들이 어떠한 상태(name, speed, size)를 가질 수 있고, 어떠한 행동을 할 수 있는지를 설명한다.
또한 이런 Class로 myCar, yourCar, outCar 각 객체는 선언되며, 속성은 모두 동일하지만 각 객체가 가질 수 있는 상태는 모두 다를 수 있다!
// example2
class Counter {
private int count = 0;
public void increment() {
count++;
}
public int get() {
return count;
}
}
Counter appleCounter = new Counter();
Counter orangeCounter = new Counter();
카운터는 어떤 것을 세는 것을 정의한 클래스
내부적으로 count(개수라는 상태), 카운트를 증가시키는 행동, 숫자를 센 값을 가져오는 행동을 기술
instantiate란?
new라는 키워드처럼 객체화시켜서 만든 객체(object)를 instance라고 말한다.
// example3
class Switch {
private int state = 0;
public void on() {
this.state = 1;
}
public void off() {
this.state = 0;
}
public boolean isOn() {
return this.state == 1;
}
}
Switch tvSwitch = new Switch();
내가 원하는 속성, 행동을 구체적으로 기술하고 이를 실체화한 것이 객체이다.
이러한 클래스와 객체의 개념은 현실세계를 효율적으로 프로그래밍으로 옮길 수 있게 된다.
코드의 재사용성과 확장성
클래스를 만들면 반복해서 객체를 생성할 수 있음 -> 생산성과 유지보수 용이
데이터와 행동을 함께 묶음
클래스는 속성(데이터)과 기능(메서드)를 하나로 묶음으로써 큰 시스템을 설계할 떄 클래스 단위로 나누면 역할 분담이 쉽다.
객체 지향 프로그래밍(OOP)의 기반
OOP는 캡슐화, 상속, 다형성을 통해 유연하고 강력한 프로그램을 만듦
클래스와 객체가 없다면 이러한 구조적 설계가 불가능
변수와 값
변수란 값을 담을 수 있는 이름이 있는 그릇!
변수는 어떠한 객체가 있는 주소나, 실제 값이 담긴다. ex) 1, “안녕”, Object(“곡괭이”)
변수는 값이 바뀔 수 있다.
클린코드를 위해서는 변수를 꼭꼭꼭 모르는 사람이 봐도 이해하기 쉽게 적자!
함수
아래에 2개 중 무엇이 함수인가?
class Add:
def add(a, b):
return a + b
vs
def add(a, b):
return a + b
함수란?
독립적으로 존재하며 임무(task)를 수행하는 코드들의 집합
함수 이름으로 호출한다.
매개변수를 받을 수도 않을 수도 있다.
결과 값을 리턴할 수도 안할 수도 있다
재사용이 가능하다
매서드란?
객체 혹은 클래스에 종속되어 임무를 수행하는 코드들의 집합
클래스나 객체의 상태 정보에 접근 가능
매소드는 객체의 상태에 영향을 받기에, 같은 클래스로 선언된 메소드더라도, 객체 혹은 클래스에 종속되어 임무를 수행한다!
그래서 질문에 대한 대답은, 객체의 상태에 영향을 받는 클래스의 add는 메소드, 그냥 add는 함수이다!
변수와 객체는 메모리에 어떻게 저장되는가?
어플리케이션은 어떻게 실행되는가?
어플리케이션은 일반 사용자가 사용할 기능을 제공하는 컴퓨터가 실행할 수 있는 명령어들의 집합
메모리는 실행된 애플리케이션이 상주하는 곳 => 어플리케이션이 메모리에 있어야 실행이 가능하다.
public class Main {
public static void main(String[] args){
int a = 7;
int b = 3;
int c = a + b;
}
}
a = 7이라는 명령을 cpu에서 실행하고, 이를 메모리에 7이란 값을 올리고, 그 곳에 a라는 이름을 붙임
b = 3이라는 명령을 cpu에서 실행하고, 이를 메모리에 3이란 값을 올리고, 그 곳에 a라는 이름을 붙임
…
이런 식의 명령과 저장이 계속되는 것.
runtime => application이 메모리에 올려져서 실행되고 있는 순간을 말한다.
사실, 이런 변수와 변수의 연산과정만이 아닌, 함수도 메모리에 저장된다.
메모리 구조
애플리케이션에 할당되는 메모리는 stack 메모리와 heap 메모리 등의 여러 영역으로 나눠진다.
| 메모리 영역 | 역할 | 주의 점|
| -------- | --------- | --------- |
| Stack | 함수나 메서드의 지역 변수와 매개 변수가 저장되는 곳, 함수나 메서도가 호출될 때도 스택 프레임이 쌓인다. | 스택 프레임은 개발자가 이를 신경 쓸 필요는 보통 없지만, 함수를 재귀적으로 많이 호출하여 스택 메모리 이상을 저장하게 되면 문제가 발생한다.|
| Heap | 객체가 저장되는 공간 | |
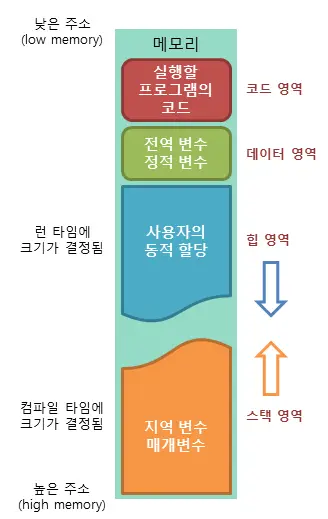
// example
public class Main {
public static void main(String[] args) { // 매개변수
Counter c = new Counter(); // 객체, 지역 변수
}
}
public class Counter {
private int state = 0; //상태를 나타내는 instance 변수
public void increment() {
state++;
}
public int get() {
return state;
}
}
3가지 변수가 존재!
객체가 클래스로 부터 생성될 때 생성자가 실행되는 스택프레임이 먼저 생성되고, 이것이 힙에 객체를 생성한 후, 스택프레임이 사라진다. 이때 생성자 스택 프레임에서 this라는 보이지 않는 변수가 힙 주소를 저장하였다가 반환한다.
그리고 해당 stack의 지역변수로 객체가 선언되었으므로, 스택 프레임에 방금 생성된 객체의 heap 주소가 저장된다.
매서드 역시도 stackframe을 통해 생성되며, 매서드는 객체에 종속되어있는데 이 정보가 this를 통해 어떤 객체를 가리키도록 생성된다.
호출된 함수나 매서드는 파라매터로 해당 객체의 주소를 전달받아 상태를 변경시키면, 해당 함수나 매서드가 종료되어 스택메모리에서 사라지더라도 변화된 정보는 힙 메모리에서 유지된다.
쓰레기 객체(garbage object)
public class Main {
public static void main(String[] args) {
Counter c = make();
}
public static Counter make() {
Counter c = new Counter(); // => 새로운 객체를 heap에 생성 그러나 이를 전달해주지 않고
return new Counter(); // => 새로운 객체를 heap에 생성해 전달
}
}
public class Counter {
private int state = 0;
public void increment() {
state++;
}
public int get() {
return state;
}
}
위의 예시처럼 접근할 수 없는 객체가 생겨버리면, 쓸모없는 객체가 heap 메모리를 차지하게 된다. 이런 객체를 쓰레기 객체라고 한다.
이런 것을 삭제해주기 위해 2가지 방법이 있다.
개발자가 직접 해당 객체를 지정해 메모리를 해제
gc(garbage collector)를 지원하는 언어에서 이러한 객체를 자동으로 삭제
파이썬은 모든 것이 객체이기 때문에
def wow(num):
print(num)
a = 1
wow(a)
파이썬은 모든 것을 객체로 저장하기 위해 스택에 올릴 때 글로벌 프레임을 사용한다.
-
nnUNet 서비스 구현
개요
목적
nnUNet 서비스의 내부 기능을 구현한다.
문제 상황
Cleancode 설계 원칙에 따라, 각 모듈을 분리하려 했으나, 분리에 기준을 명확하게 정하고, 이를 기록할 필요성이 느껴졌다.
I/O 기능을 분리하여 단일책임 원칙 준수
I/O 기능이 Feature 추출, TotalSegmentator 기능 등에 결합되어 경로 -> 실행 구조를 따르고 있다.
해당 구조를 수정하지 않으면 한번에 I/O 각 기능에 실행이 아닌, 각 기능을 실행할 때마다 I/O가 실행되어야 하는 불편함이 따른다.
각 모듈의 가독성과, 유지/보수성 증가를 위한 Clean Code를 어떻게 설계해야하는가.
단일책임 원칙 준수, 의존성 주입, 인터페이스 통일에 원칙을 준수하여 코드를 설계
그러나 이러한 원칙에 따라 코드를 분류할 때 어떤 코드를 같은 파일에 어떤 코드를 일반화시킨 I/O 등의 모듈에 넣어야할지 기준의 모호함이 발생
해당 모호함을 코드 변경 사유에 따라 정리하기 위해 각 코드들의 목적에 대한 정리가 필요.
결국 핵심은 현재 서비스를 만들 때 각 모듈 단위의 추상화를 통해서, 인터페이스를 이해하기 쉽게 정리하고, 교체를 용이하게 만드는 것
변경의 이유를 분리하라 (SRP)
같이 바뀌는 것끼리 묶고, 따로 바뀌는 건 나눈다.
변경 이유가 다른데 같이 묶으면 나중에 다 같이 바뀌는 지옥이 됨
인터페이스는 용도 기준으로 만들라
데이터의 타입이 아니라, 역할과 목적을 기준으로 묶어야 함
❌ 잘못된 추상화
✅ 올바른 추상화
“이미지와 관련된 걸 ImageUtils에 다 넣자”
“AI 모델의 입력 생성 → FeatureExtractor”
구체적인 것이 아니라, 의도를 표현하라
함수/클래스명, 모듈명은 무엇을 한다가 아니라 왜 한다를 표현
❌ 잘못된 추상화
✅ 올바른 추상화
load_image, save_image, sitk2nib
DataAdapter (형식 변환의 책임)
make_ap_image, extract_mask
FeatureBuilder (모델 입력 생성의 책임)
추상화는 실제 사용 사례를 최소 2개 생각하고 하라
“지금 하나만 있을 때는 절대 추상화하지 마라” → 재사용 포인트가 최소 2개 이상일 때 추상화가 필요
하나만 있을 때 수행하는 추상화는 다른 재사용 포인트가 생길 때 문제가 될 확률이 높다(기존의 것에 맞춰져 있을 확률이 높기 때문)
인터페이스는 “최소한의 정보만 넘기도록”
함수에 다 때려 넣음 나중에 바꾸기 힘듦 → 필요한 최소한의 데이터만 넘기고, 의도를 명확히
모듈을 리팩토링할 떄 원칙을 정하자!
원칙
재사용되는 코드는 무조건 분리하기!
각 인터페이스가 최소의 정보만으로 통신이 가능하게! 조금 비효율적이더라도 일관된 구조로 통신이 가능하게!
코드가 확장이 편하도록, 전략 패턴, 어댑터 패턴 등을 적용하기!
각 모듈별로 실제 실행이 되는 usecase 부분을 각각 작성해두고, 전체 모듈의 usecase를 조립하는 pipeline 파일과, 이를 api와 연결하는 entrypoint 설계
“핵심은 코드가 어떤 식으로 수정될 수 있을까를 예상하고, 수정이 편하도록 관리하는 것이다.”
이를 위한 기능의 정리
현재 nnUNet 서비스에 존재하는 모든 기능을 정리
기능
설명
수정 가능 시나리오
일관성 제한
gRPC 통신
gRPC를 통해 API Gateway와 통신을 수행
API Gateway와 추가적인 통신 명령이 생기거나, 제거될 수 있음
case_dir만을 사용해 통신이 수행되야한다.
nnUNet 추론
이미지를 입력받아
Clean Code를 위한 코드의 정리
각 코드가 담당하는 계층의 분리
코드를 추상화하는 목적에는
나중에 해당 코드를 재사용하고 읽기 편하게 만드려는 목적
-
결산
개요
1주차 주요 이슈
1. API Gateway가 각각의 서비스에 통신할 API 구조 정리
MSA를 구성하는 서비스를 아래의 분리 원칙을 참고하여 분리 및 API 통신 구조를 설계
1. 각 서비스는 하나의 역할만 수행해야 한다.
Image -> mask를 만드는 기능, mask->mask를 만드는 기능, mask-> 3d obj를 만드는 기능 등등
2. 추후 오케스트레이션의 관리르 편하게 하기 위해 어떤 자원을 얼마나 소모하느냐 등의 공통점도 서비스 분리 기준으로 삼는다.
I/O가 많이 필요하다, CPU 사용량이 많다, GPU 사용량이 많다 등등
3. 각 서비스는 같은 분류에 기능에 대해 확장성에 문제가 없어야한다.
코드 설계 원칙을 참고해 각 서비스별 주요 코드를 라이브러리로 정리함으로써, 추후 해당 서비스에 추가 기능이 발생하더라도, 같은 구조 내부에서 쉽게 추가될 수 있도록 서비스를 구성
Service
EndPoint
Parameter(request)
Parameter(response)
Detail
Constraints
nnUNet
inference/totalseg
image_path : str
mask_path : str
totalSegmentator를 실행시켜, 해당 이미지에 대한 Organ Mask를 저장하고, 저장한 Path를 반환
1mm보다 high resoulution을 가지는 이미지에 대해서는 더 나은 결과를 낼 수 없다
nnUNet
inference/vessel
image_A_path : str, image_P_path : str
mask_path : str
2개 이미지의 파일 경로를 받아 image_A_path와 같은 물리적 공간을 가지는 신장,동맥,정맥 mask를 저장하고 해당 주소를 반환
A, P Phase에 해당하는 CT 이미지에 대해서만 유효한 결과를 낼 수 있다
nnUNet
inference/ureter
image_D_path : str
mask_path : str
이미지 파일경로를 받아, 같은 물리적 공간을 가지는 요관, 신장 mask를 저장하고 해당 주소를 반환
D Phase .nii.gz에만 유효한 결과를 낼 수 있다
nnUNet
inference/tumor
image_path : str
mask_path : str
이미지의 파일 경로를 받아, 같은 물리적 공간을 가지는 신장, 종양 mask를 저장하고 해당 주소를 반환
Smoothing
smoothing/base
mask_path : str
obj_path : str
마스크의 파일 경로를 받아, 해당 마스크에 대한 3d obj파일을 만들고, 그 주소를 반환
mask의 label number가 사전에 약속된 규칙을 따라야함
postprocess
postprocess/fat
mask_path : str
mask_path : str
kidney, tumor, total 마스크를 기반으로 Fat mask를 생성해주고, 해당 경로를 반환
사전에 약속된 mask 규칙을 따라야함
postprocess
postprocess/sample
mask_path : str, templete_path : str
mask_path : str
템플릿과 환자 mask(kidney, tumor가 있는)를 기반으로 빠른 mask를 생성해주고, 해당 경로를 반환
사전된 약속된 mask label number를 따라야함
postprocess
postprocess/vessel
mask_path : str
mask_path : str
결과 마스크를 기반으로 떨어진 artery를 자동 연결하는 후처리 기능을 적용 후 저장, 그 경로를 반환
사전에 약속된 mask label number 규칙을 따라야함
postprocess
postprocess/ureter
mask_path : str
mask_path : str
결과 마스크를 기반으로 떨어진 ureter를 자동 연결하는 후처리 기능을 적용 후 저장, 그 경로를 반환
사전에 약속된 mask label number 규칙을 따라야함
2. Clean code를 위한 원칙 설정
Single Responsibility
정의
하나의 클래스나 모듈은 오직 하나의 책임(변경 이유) 만 가져야 한다.
문제점
기존 코드에서 nnUNet 실행, preprocessing, 이미지 처리 등 여러 기능이 하나의 파일에 혼재되어 있다. → 재사용성과 유지보수성 저하
개선방향
각 모듈을 인공지능을 실행하는 모듈, 이미지와 메타데이터 정보를 얻는 모듈, 인공지능 실행 클래스를 생성하는 모듈 등 하나의 역할만 수행하도록 구조를 변경한다.
코드의 가독성과 재사용성을 강화
Dependency Inversion Principle(의존성 역전 원칙)
정의
상위 모듈은 하위 모듈의 구현이 아니라, 추상화(인터페이스/프로토콜) 에 의존해야 함.
문제점
nnUNet 사용 시, network, Predictor 등 객체를 직접 생성하고, 하드코딩된 파라미터를 사용하는 부분이 존재한다.
개선방향
config.yaml을 통해 하드 코딩되는 원인인 공통된 파라매터를 한 곳에 관리한다.
팩토리 패턴 또는 DI 컨테이너를 이용해 객체를 생성하여 공통된 모듈을 활용하더라도 다른 모델이나 구조를 쉽게 교체 가능하게 설계한다.
Interface 통일 (프로토콜 정형화)
정의
여러 서비스가 공통된 메서드/구조/데이터 포맷을 따라야 함.
문제점
nnUNet과 달리 post-processing 서비스는 mask 이미지 -> mask 이미지를 생성하는 구조는 동일하지만, 해당 내용을 구현하는 코드 등에서 각각의 연구 내용에 따라 실행되는 로직이 상당히 다르다. 하지만 백엔드 입장에서는 마스크 -> 마스크를 생성하며 그때 마다 요구하는 label_name:label_num이 달라진다는 공통된 특징을 가지고 있다.
그렇기에 서로 다른 로직의 모듈을 관리하는 post-processing 서비스에서 프로토콜 정형화가 필요하다.
개선방향
공통 부모 클래스/프로토콜 정의
run(), save_output(), load_input() 등의 인터페이스 통일
Fali Fast & Logging
정의
오류가 발생하면 빠르게 실패하고, 즉시 원인을 알려야 함.
문제점
의료 데이터는 실행시간이 길고 리소스 소모가 큼
중간 실패를 늦게 알아채면 자원 낭비 발생
개선방향
초기 유효성 검사 강화 (파일 경로, config 유효성 등)
예외 발생 즉시 서비스 종료 및 명확한 로그 출력
로그는 표준화된 포맷과 단계별(Level별) 로깅 적용 (INFO, WARNING, ERROR)
모니터링 도구와 연계할 수 있도록 구조화된 로그(JSON 등) 제공 검토
3. MSA를 만들기 위해 고려되야할 추가적인 요소
Fail Fast 및 Logging을 전체 서비스 단위로 실행될 수 있게하는 logging 및 benchmark 시스템의 구성
MSA로 서비스가 변경되면서, 각 구조가 서로 다른 코드 환경이 gRPC로 통신하기에, 오류가 발생할 시 디버깅이 어려워지고, 문제가 발생했을 때 바로 알아차리기가 어려워진다.
이 점을 해결하기 위해 각 코드를 설계할 때 문제가 발생하면 대처할 수 있는 방안이 녹아드러야 하며, 전체 서비스 환경에서 log를 모으고 볼 수 있어야 한다.
Orchstration
nnUNet 서비스를 구현하며, API Gateway에서 각 서비스로 요청하고 각각의 기능을 각 AI의 inference 및 결과 저장까지 추상화를 완료하였지만, 실제 BE 서버가 요청하는 것은 하나의 이미지를 추론하여 저장하는 요청이 아닌, 하나의 케이스를 전달했을 때 각 AI 모델을 모두 활용하여 완전한 결과를 만드는 것이다.
이를 위해 API Gateway에서 각 기본 기능을 요청하는 것과, 이를 실제 BE 요청에 맞추어 통합실행하는 오케스트레이션 모듈을 생성하여, 이 곳에서 추상화를 통해 각 기능을 통합하는 모듈을 완성해야한다.
문서화
MSA를 구현하면서, 서비스끼리의 통신, 모듈끼리의 추상화를 통한 연결관계 등 재사용성을 위해 하나에 모여있던 코드들을 분리하고, 의존성 주입을 통해 생성하게 함로써 이러한 전체적인 구조가 정리될 필요성을 느꼈다. 그렇기에 시스템 흐름도 등 소프트웨어 공학에서 배운 각 모듈들의 의존관계 및 파라매터를 정리하는 과정이 필요하다.
docker-compose화
현재의 시스템은 DockerFile을 만들어 두고 사전에 마운트 정보다, 연결된 docker network 이름 등을 사전에 미리 적어둔 shell 파일인 run.sh 파일을 실행시킴으로써 이미지 빌드와 컨테이너 실행에 필요한 정보를 재사용한다. 하지만 MSA로 만들어서 이런 기능등을 k8s같은 오케스트레이션 시스템이 관리하기 위해선 이를 docker-compose로 변경하여 관리를 해야한다.
완성된 기능
gRPC를 통한 통신 기능
proto 파일을 통해서 통신 구조를 정의하고, 공유된 data 마운트에서 통신한 경로 정보를 활용해 데이터를 가져오는 구조를 완성
nnUNet 서비스 <-> API Gateway 기본 통신
totalsegmentator 기능이 통신을 통해 실행되고, 결과를 저장하고, 저장된 파일 경로를 응답하는 구조의 완성
그리고 다른 vessel, ureter, tumor가 통신할 구조의 완성
-
연구 기능 통합
개요
목적
Docker Container로 백엔드 내에서 nnUNet을 활용하는 연구 프로젝트 서비스를 완전히 분할하고, Image를 활용하는 부분은 하나로, 나머지 기능은
각각 배포환경을 다르게 구성하여, microservice처럼 각 기능을 연결한 프로젝트 제작하기
요구조건
nnUNet의 .nii.gz 데이터를 ndarray + props(nnUNet을 코드 상에서 실행하기 위한 또 다른 입력값)으로 추출해주는 SitkIO 함수를 활용해 I/O 횟수를 최소화(각 모델들을 한번의 I/O로 모두 실행가능하게)
메모리 소모량을 감소시키기 위해 각 알고리즘 실행 과정 속, 필요로 하는 최소값의 해상도로 알고리즘 수행
향후 다른 연구의 결합에 대한 유지/보수성 증가를 위해 CT Image를 직접적으로 활용하지 않는 다른 기능들은 따로 수행될 수 있도록 구성
구체화
Service
Index
Detail
nnUNet
1
혈관, 요관, 구 버전 신장/종양, 구 버전 요관을 모델 별로 함수를 나누어 ndarray -> ndarray 구조로 각각 실행될 수 있도록 모듈화
nnUNet
2
조건에 따라 모델을 선택해, 해당 함수가 실행될 수 있도록 구조화 및 입출력 구조 요구조건 달성
(optional) nnUNet
3
빠르게 샘플을 만드는 기능을 추가, 만약 이를 추가할 거라면, 해당 서비스와 nnUNet 서비스가 병렬적으로 실행되고, obj 파일을 연속해서 업로드가 수행되야함
Smoothing
1
.nii.gz mask -> obj 파일로 만드는 업데이트된 기능(FE에 기능을 활용하기 위해선 해당 로직에 업데이트가 필요)
post-processing
1
인공지능 inference 결과와, mask 결과를 활용하여 Fat mask를 추가해주는 기능
(optional) post-processing
2
nnUNet의 기능을 후처리 작업을 통해 보정해주는 역할
API Gateway
1
nnUNet 관련 기능, Smoothing 관련 기능, post-processing 관련 기능을 각각 container로 나누어 이를 연결해주는 역할
발견된 문제
1. 서비스에 분할에 관하여
마이크로 서비스로 얻고 싶었던 이점은 아래와 같았다.
1. 각 연구자들의 새로운 연구결과를 결합할 때 도커로 배포만 가능하면, monolithic에 결합하는 수고 없이, 통신으로 이를 해결
2. 각 연구자들의 연구 결과를 분리함으로써 다양한 라이브러리 사용되는 배포환경의 충돌 방지
그러나 현재의 백엔드 시스템은 연구자들이 주로 사용하는 nnUNet이라는 AI 아키텍쳐를 활용할 때 용량이 큰 의료이미지의 I/O 병목을 줄이기 위하여 , 해당 파일을 한번 불러오고, 저장 없이 전처리, AI inference, 후처리를 수행한 후 최종 결과만을 저장하여, 이를 활용한다. 이를 구현하기 위해선 각 서비스별로 I/O를 수행하지 않고, 모든 연구결과를 활용하기 위해서는 해당 서비스가 monolithic하게 존재해야한다.
이는 현재 마이크로 서비스를 만드려는 목적과 상충하는 결과이다.
그렇기에 앞으로 마이크로 서비스를 제작할 때는, 데이터 크기가 큰 의료이미지의 특성에 따라 발생하는 아래와 같은 문제를 고려해야한다.
1. 의료 '이미지'는 용량이 매우 크기에 I/O 병목이 존재하며, gRPC로 이미지 자체를 넘기는 것은 비효율적이다.
2. 여러 서비스가 각각 이미지를 병렬적으로 로드하고 처리한다면, 이에 따른 메모리 소모량을 고려해야한다.
3. 각 연구는 다양한 라이브러리를 사용하기에 이를 하나의 배포환경에 합쳐버리면, 유지/보수 및 안정성이 상당히 떨어진다.
이러한 문제를 해결하기 위한 아이디어는, 몇몇 서비스들은 의료이미지를 필수로 활용하진 않는 것이다. mask 데이터는 의료 이미지 데이터에 비해 훨씬 용량이 작으며,
이에 대한 I/O를 수행하는 것은 이미지에 비해 훨씬 작업 소모량이 적다.
그렇기에 이미지를 다루는 연구 결과물들은 성능 최적화를 위해 monolithic하게 수행할 수도 있겠지만, mask에 대한 처리를 수행하는 로직들에 대해서는
서비스를 나누는 것을 고려할 수 있다.
속도의 향상과 유지/보수성의 tradeoff를 고려하여 문제를 해결할 방법이 필요하다.
-
Service:nnUNet 개발
개요
목적
nnUNet과 torch를 사용하는 각 연구 성과를 통합한 nnUNet 서비스의 개발
요구조건
nnUNet의 .nii.gz 데이터를 ndarray + props(nnUNet을 코드 상에서 실행하기 위한 또 다른 입력값)으로 추출해주는 SitkIO 함수를 활용해 I/O 횟수를 최소화(각 모델들을 한번의 I/O로 모두 실행가능하게)
메모리 소모량을 감소시키기 위해 각 알고리즘 실행 과정 속, 필요로 하는 최소값의 해상도로 알고리즘 수행
각각의 Container에 그냥 OS를 활용하는 이미지를 쓰지말고, Container의 용량을 감소시키는 작은 이미지를 활용할 것
3차 회의 요구사항
백엔드 개발자와 기존의 nnUNet 기능만을 통합하는 과정이 아닌, Smoothing, PostProcessing 기능 까지 고려하는 2번째 시스템 개발에 관하여 회의를 진행
마이크로 서비스를 수행할 때 Docker Image 경량화에 대한 이슈
이미지가 무거우면 빌드 시간, 배포 시간, 디스크 사용량, 네트워크 트래픽 모두 증가함.
각 Pod이 이미지 Pull을 할 때 용량이 작을수록 빠르고 안정적.
smoothing, post-processing 서비스를 분리하면서 다른 기능들은 mask에 한정해서는 I/O가 필요하고, 기존의 저장되던 Segmentation 이외의 다른 정보를 저장할 필요성이 대두
해당 사항에 대해 TotalSegmenatator 혹은 inference 결과 등을 mask 디렉토리에 저장하고 활용하는 것에 대해 문제가 없음을 확인
서비스 API
Service
EndPoint
Parameter(request)
Parameter(response)
Detail
Constraints
nnUNet
inference/totalseg
image_path : str
mask_path : str
totalSegmentator를 실행시켜, 해당 이미지에 대한 Organ Mask를 저장하고, 저장한 Path를 반환
1mm보다 high resoulution을 가지는 이미지에 대해서는 더 나은 결과를 낼 수 없다
nnUNet
inference/vessel
image_A_path : str, image_P_path : str
mask_path : str
2개 이미지의 파일 경로를 받아 image_A_path와 같은 물리적 공간을 가지는 신장,동맥,정맥 mask를 저장하고 해당 주소를 반환
A, P Phase에 해당하는 CT 이미지에 대해서만 유효한 결과를 낼 수 있다
nnUNet
inference/ureter
image_D_path : str
mask_path : str
이미지 파일경로를 받아, 같은 물리적 공간을 가지는 요관, 신장 mask를 저장하고 해당 주소를 반환
D Phase .nii.gz에만 유효한 결과를 낼 수 있다
nnUNet
inference/tumor
image_path : str
mask_path : str
이미지의 파일 경로를 받아, 같은 물리적 공간을 가지는 신장, 종양 mask를 저장하고 해당 주소를 반환
개발과정
DockerFile 작성
고려사항
현재 BE 시스템에서 기존에 사용하던 torch version = 2.2.2, cuda가 존재하여 GPU를 사용할 수 있어야 한다.
totalsegmentator, nnunet이 사용 가능해야한다.
gRPC 기반 api endpoint 설정
api service와 nnUNet에 해당하는 docker container 제작, 공유된 볼륨에 동일한 경로로 접근 가능한지 테스트
통신 담당 함수와, 각 통신 결과를 각 함수에 전달하는 entrypoint 함수 제작
현재 생각한 구조
각 서비스는 통신 함수를 main.py로 가지며, 해당 main.py와 동일한 디렉토리에 각 서비스가 구성된 라이브러리가 존재
각 라이브러리는 api에 따라 1:1로 실행되는 함수 entrypoint를 가지며, 이를 라이브러리 최상단에 위치
라이브러리 내부에서 각 함수에 따라 구동되는 기능별로 폴더를 구분하며, utils 폴더에 잡다한 기능들을 넣어두기
각 서비스 별로 통일된 라이브러리 선언 규칙이 필요
totalSegmentator 함수 제작
진행 과정
totalsegmenator 라이브러리 설치 => 발견된 문제, warning으로 현재 사용하고 있는 라이브러리 중 하나가 2025.12.30에 사라질 예정이라고 함, 오류가 발생했을 때 참고
totalsegmentator는 RAM, GPU 사용량이 필요함, 현재 docker ram 사용량이 MB단위임을 발견, totalsegmentator를 구동시키기 위해 20GB로 변경, 다만 서버 컴퓨터의 스펙은 로컬 개발환경과 다르게 128GB의 램을 보유하고 있으므로, 해당 Docker Container는 100GB정도까지 가도 괜찮을 듯 하다.
totalsegmentator를 돌릴 시 멀티프로세싱을 사용하기 때문에 이를 gRPC와 함께 사용할 떄 fork관련 이슈가 발생, main 함수에 multiprocessing을 import해주고, 미리 조치를 취하면 괜찮지만 이게 왜 문제가 생기는지에 대한 고찰이 필요.
테스트 진행 완료 mask/total_A.nii.gz로 저장 밑 return이 잘 수행됨을 확인
API Gateway에서 inference/totalseg를 case 폴더 -> 각 이미지 폴더로 어떤 식으로 연결을 지어야할지에 대한 고찰이 필요
추후 체크리스트
BE->API Gateway와 inference/totalseg API에 대한 연결을 어떻게 수행할 것인가.
멀티 프로세싱 fork관련 이슈가 왜 발생하는가.
nnUNet pth 파일 기반 교체 가능한 함수 개발
vessel Feature 추출 함수 개발
-
API 설계
개요
설계 개요
연구원들의 모든 연구 내용 기능을 통합하기 위해, 아래와 같은 전체 구조를 설계하였다.
기존의 BE 시스템 <-> API Gateway <-> 각 서비스
기존의 BE 시스템에서 CT Image를 기반으로 mask와 obj 파일을 생성하는 구조를 아예 분리함으로써, monolithic하게 운영되고 있던 BE 시스템의
라이브러리 충돌 가능성을 줄이고, 각 연구 결과를 각각의 서비스로 분리함으로써 기존에 존재하였던
torch 및 기반이 되는 nnUNet 라이브러리가 업데이트되었음에도 적용이 힘들었던 점.
각 연구가 사용하는 라이브러리가 너무 다양해 monolithic한 시스템에 적용하기 힘들었던점
새로운 기능을 추가할 때마다, 해당 기능과 BE를 연결할 때 코드 구조를 바꿔야할 필요가 생기는 점
같은 문제를 해결하기 위해, 연구 분야에 관련해 BE 시스템에서 분리하고, MSA처럼 운영하기 위해 전체 구조를 설계하였다.
서비스 분리 기준
nnUNet 서비스
혈관, 신장, 요관, 종양 등의 segmentation 기능을 AI Inference를 통해 수행하는 서비스
nnUNet과 그 기반 라이브러리(torch 등)에 의존하는 기능들을 통합, 관련 라이브러리가 업데이트될 때 적용하기 쉽게 통합
세부 기능별로 지나치게 분리하지 않되, nnUNet 기반의 서비스들을 모아두어, 모델 파라매터 파일만 교체한다면 쉽게 유지/보수가 가능하게 하나의 서비스로 구성
AI inference를 위해 GPU가 많이 필요하기 때문에, 별도 서비스로 분리
Smoothing 서비스
.nii.gz 마스크 파일을 3D Object 파일(.obj)로 변환하면서 Smoothing을 적용하는 후처리 기능을 담당
해당 기능은 trimesh, pyvista, open3d 등 3D 라이브러리를 사용하며, 관련 기능을 nnUNet 서비스는 필요로하지 않으므로, 유지/보수 성 증가를 위해 분리
해당 기능은 GPU 성능을 크게 필요로 하지 않으며, nnUNet 서비스의 결과물을 활용하여 3d obj를 만드는 역할이므로 기능을 분리하는 관점에서 서비스를 분리
Post-Processing 서비스
inference 결과를 후처리하여 Fat mask 추가, cugraph 기반 skeleton 재구성 등의 기능을 수행
nnUNet과 달리 GPU보다는 CPU 집약적인 작업이 많아 자원 관리 측면과 기능 분리 측면에서 서비스를 분리하는 것이 유리
라이브러리도 nnUNet, Smoothing 서비스에서 사용하는 라이브러리가 아닌 cugraph, skimage 등 다른 라이브러리를 주로 사용하느모 업데이트가 용이하게 분리
요구조건
nnUNet의 .nii.gz 데이터를 ndarray + props(nnUNet을 코드 상에서 실행하기 위한 또 다른 입력값)으로 추출해주는 SitkIO 함수를 활용해 I/O 횟수를 최소화(각 모델들을 한번의 I/O로 모두 실행가능하게)
메모리 소모량을 감소시키기 위해 각 알고리즘 실행 과정 속, 필요로 하는 최소값의 해상도로 알고리즘 수행
향후 다른 연구의 결합에 대한 유지/보수성 증가를 위해 CT Image를 직접적으로 활용하지 않는 다른 기능들은 따로 수행될 수 있도록 구성
각각의 Container에 그냥 OS를 활용하는 이미지를 쓰지말고, Container의 용량을 감소시키는 작은 이미지를 활용할 것
API 설계
API Gateway API 설계
Service
EndPoint
Parameter(request)
Parameter(response)
Detail
Constraints
nnUNet
inference/totalseg
image_path : str
mask_path : str
totalSegmentator를 실행시켜, 해당 이미지에 대한 Organ Mask를 저장하고, 저장한 Path를 반환
1mm보다 high resoulution을 가지는 이미지에 대해서는 더 나은 결과를 낼 수 없다
nnUNet
inference/vessel
image_A_path : str, image_P_path : str
mask_path : str
2개 이미지의 파일 경로를 받아 image_A_path와 같은 물리적 공간을 가지는 신장,동맥,정맥 mask를 저장하고 해당 주소를 반환
A, P Phase에 해당하는 CT 이미지에 대해서만 유효한 결과를 낼 수 있다
nnUNet
inference/ureter
image_D_path : str
mask_path : str
이미지 파일경로를 받아, 같은 물리적 공간을 가지는 요관, 신장 mask를 저장하고 해당 주소를 반환
D Phase .nii.gz에만 유효한 결과를 낼 수 있다
nnUNet
inference/tumor
image_path : str
mask_path : str
이미지의 파일 경로를 받아, 같은 물리적 공간을 가지는 신장, 종양 mask를 저장하고 해당 주소를 반환
Smoothing
smoothing/base
mask_path : str
obj_path : str
마스크의 파일 경로를 받아, 해당 마스크에 대한 3d obj파일을 만들고, 그 주소를 반환
mask의 label number가 사전에 약속된 규칙을 따라야함
postprocess
postprocess/fat
mask_path : str
mask_path : str
kidney, tumor, total 마스크를 기반으로 Fat mask를 생성해주고, 해당 경로를 반환
사전에 약속된 mask 규칙을 따라야함
postprocess
postprocess/sample
mask_path : str, templete_path : str
mask_path : str
템플릿과 환자 mask(kidney, tumor가 있는)를 기반으로 빠른 mask를 생성해주고, 해당 경로를 반환
사전된 약속된 mask label number를 따라야함
postprocess
postprocess/vessel
mask_path : str
mask_path : str
결과 마스크를 기반으로 떨어진 artery를 자동 연결하는 후처리 기능을 적용 후 저장, 그 경로를 반환
사전에 약속된 mask label number 규칙을 따라야함
postprocess
postprocess/ureter
mask_path : str
mask_path : str
결과 마스크를 기반으로 떨어진 ureter를 자동 연결하는 후처리 기능을 적용 후 저장, 그 경로를 반환
사전에 약속된 mask label number 규칙을 따라야함
BE - API Gateway API 설계
추후 백엔드 담당자와의 토의 필요
-
nnUNet 관련 기능 분리
개요
목적
2차 회의를 수행하고, 해당 내용을 적용하기 위해 기능 구현을 구체화하여 구현하는 과정을 정리
구체화
gRPC를 활용하여 서로 다른 Docker Container간 str, List[str] 통신을 활용가능하고, 공유된 마운트 Volume에 동일한 Path로 접근가능하게 구현
Server를 아래 2가지 옵션으로 구현
각종 ai관련 기능을 모두 통합한 monolithic한 서비스
혈관, 요관, 신장 등 각각 기능들을 microservice로 분리하고, 모두 동일한 volume mount에서 경로만 통신해 통합된 기능을 제작
정해진 서버의 옵션에 따라 요구사항에 맞춘
Resize기능
각종 nnUNet 취사선택 기능
(optional) 빠른 샘플 제작 기능
을 구현할 수 있도록 수행한다.
개발일정
Date
To Do
Process
~07.09
gRPC를 통한 통신 구조 및 볼륨 마운트를 통해 동일한 파일 접근 가능한지 테스트 수행
완료(07.09~07.09)
~07.10
monolithic하게 구현할지, microservice로 구현할지 결정
진행(07.09~)
~07.13
nnUNet을 Path만 가지고 있으면, Phase에 따라 실행하는 구조 생성
~07.14
optional한 기능의 구현가능성에 따라 추가
발견된 문제
1. 서비스에 분할에 관하여
마이크로 서비스로 얻고 싶었던 이점은 아래와 같았다.
1. 각 연구자들의 새로운 연구결과를 결합할 때 도커로 배포만 가능하면, monolithic에 결합하는 수고 없이, 통신으로 이를 해결
2. 각 연구자들의 연구 결과를 분리함으로써 다양한 라이브러리 사용되는 배포환경의 충돌 방지
그러나 현재의 백엔드 시스템은 연구자들이 주로 사용하는 nnUNet이라는 AI 아키텍쳐를 활용할 때 용량이 큰 의료이미지의 I/O 병목을 줄이기 위하여 , 해당 파일을 한번 불러오고, 저장 없이 전처리, AI inference, 후처리를 수행한 후 최종 결과만을 저장하여, 이를 활용한다. 이를 구현하기 위해선 각 서비스별로 I/O를 수행하지 않고, 모든 연구결과를 활용하기 위해서는 해당 서비스가 monolithic하게 존재해야한다.
이는 현재 마이크로 서비스를 만드려는 목적과 상충하는 결과이다.
그렇기에 앞으로 마이크로 서비스를 제작할 때는, 데이터 크기가 큰 의료이미지의 특성에 따라 발생하는 아래와 같은 문제를 고려해야한다.
1. 의료 '이미지'는 용량이 매우 크기에 I/O 병목이 존재하며, gRPC로 이미지 자체를 넘기는 것은 비효율적이다.
2. 여러 서비스가 각각 이미지를 병렬적으로 로드하고 처리한다면, 이에 따른 메모리 소모량을 고려해야한다.
3. 각 연구는 다양한 라이브러리를 사용하기에 이를 하나의 배포환경에 합쳐버리면, 유지/보수 및 안정성이 상당히 떨어진다.
이러한 문제를 해결하기 위한 아이디어는, 몇몇 서비스들은 의료이미지를 필수로 활용하진 않는 것이다. mask 데이터는 의료 이미지 데이터에 비해 훨씬 용량이 작으며,
이에 대한 I/O를 수행하는 것은 이미지에 비해 훨씬 작업 소모량이 적다.
그렇기에 이미지를 다루는 연구 결과물들은 성능 최적화를 위해 monolithic하게 수행할 수도 있겠지만, mask에 대한 처리를 수행하는 로직들에 대해서는
서비스를 나누는 것을 고려할 수 있다.
속도의 향상과 유지/보수성의 tradeoff를 고려하여 문제를 해결할 방법이 필요하다.
-
2차 회의 - 추가 요구사항 발생
추가 요구사항
현 진행상황
백엔드 서버를 구성하기 위해, 어떠한 백엔드 구성요소가 있고, 우리가 유지/보수, 최적화, 인수인계 가능성을 고려하여
어떠한 프레임워크들을 각 백엔드 구조에 활용할지 조사를 진행중
각 연구 프로젝트를 공유가 용이하기 위해 Docker로 구성을 변경
문제상황
백엔드 서버를 구성하기 위해, 어떤 프레임워크를 사용해야 하는가에 대한 조사를 수행하던 중,
2주 내로 각 연구의 결과물인 기능들을 통합하고, 하나의 제품으로 기능할 수 있도록하는 클라이언트의 요구사항이 발생
데드라인 이내에 해당 기능을 만들 수 있도록, 기존에 조사한 내용인 gRPC 기반의 microservice로 백엔드를 구성하는
인공지능 + 알고리즘 부분을 마이크로 서비스로 구현해, 기존의 백엔드와 연결되도록 만들 필요가 발생
해결방안
기존의 백엔드 담당자와 이 문제를 어떻게 해결할지 논의를 수행한 후 결론을 아래와 같이 내렸다.
기존의 백엔드는 아래와 같이 기능이 수행된다.
1, 2 Model(각각 담당하는 mask가 다르다.)
N CT Image |--------| N mask
A CT Image | | A mask
---> | Model | --->
P CT Image | | P mask
D CT Image |________| D mask
그러나 현재의 ai 알고리즘은 퀄리티 좋은 결과를 위해 각각의 담당하는 mask 별로 일부 mask만 생성이 가능하다.
vessel model
|--------|
A CT Image | |
---> | Model | ---> A mask
P CT Image | |
|________|
ureter model
|--------|
| |
D CT Image ---> | Model | ---> D mask
| |
|________|
kidney/tumor model
N CT Image |--------| N mask
A CT Image | | A mask
---> | Model | --->
P CT Image | | P mask
D CT Image |________| D mask
해당 과정을 수행하기 위해서는 우리는 각 Phase CT가 존재하는 경우, 향상된 알고리즘을 적용해 퀄리티가 좋은 결과를
존재하지 않는 경우, 퀄리티는 낮더라도 일반화가 잘된 기존의 모델을 활용하여 알고리즘 서비스 부분 백엔드 컨테이너를 구성해야한다.
기존의 백엔드와 결합을 위한 요구사항
image와 mask를 저장할 디렉토리의 절대경로가 함수의 입력값으로 주어질 것이다.
각 도커 컨테이너들은 공유된 하나의 볼륨을 마운트하여, 동일한 경로로 접근이 가능해야한다.
해당 알고리즘을 활용하여, 각 이미지 Phase에 해당하는 mask를 출력으로 줄 수 있어야 한다.
메모리 절약을 위해 인공지능이 필요한 정도의 spacing으로 이미지를 압축시켜 메모리 사용량을 줄여야한다.
따라서 아래와 같은 백엔드 컨테이너를 구성할 것이다.
Step 0. 각 컨테이너는 gRPC를 통해서 파일 경로를 주고 받을 수 있어야한다.
그래서 예시 파일로 케이스 주소를 전달하는 Client Container, 해당 주소를 활용해 아래 Step을 실행하는 Server Container로 예시를 만든다.
Step 1. 입력 폴더에 존재하는 이미지를 ai의 조건들을 분석하여, 그 중 가장 high resolution으로 resample해 임시로 저장한다.(모든 작업이 종료된 후 삭제 필요)
Step 2. 아래의 조건에 따라 AI 알고리즘을 적용하여 결과값을 얻어낸다.
Condition 1. A, P, D Phase가 존재할 때
1. A mask에 혈관, 종양, 신장 mask를 ai결과로 생성
2. D phase를 통해 생성된 요관 mask를 A phase로 옮겨 최종 결과 생성
3. 최종 mask를 각각의 N, P, D 이미지로 옮겨 각각 CT에서 각 기관의 대략적인 위치를 확인할 수 있게 생성
4. 각 Phase의 최종 마스크를 저장하고, 경로를 List로 저장해 반환
Condition 2. Missing Phase가 존재할 때
Condition 2-1. A or P Phase가 Missing Phase일 때
1. N, A, P, D의 신장, 혈관에 관련된 기존의 알고리즘을 적용한다.(Model 1)
2. obj를 만드는 이미지에 대한 prior를 기존의 내용을 활용한다.
Condition 2-2. D Phase가 Missing Phase일 때
1. 요관 관련 모델을 활용하지 않는다.
해당 조건들에 따라 향상된 혈관을 RESAMPLE해 옮기던, 기존의 알고리즘으로 만든 것 + 요관 알고리즘 적용 여부를 최종 mask로 활용한다.
다만 Resample 적용 여부는 추후 필요성이 없어질 수도 있으므로, on/off가 가능하게 파라매터 입력을 받을 수 있게 한다.
Step 3. 아래와 같은 입출력 구조를 가지도록 함수를 구성한다.
input (case_directory : str, resample_condition : bool)
중간 과정 속에서 result_paths에 각 mask 결과물 실제 저장도 필요.
output (result_paths : List[str])
-
-
1. 백엔드 구성 요소 정리
백엔드 구성요소에 대하여
현 진행상황
전체 백엔드 개요도
1. 백엔드가 연결된 대상 : FrontEnd, End Device 등등
해당 내용은 백엔드의 일부는 아니지만, 백엔드는 결국 End Device 및 Front End와 통신이 수행되야하므로, 해당 내용들이 어떠한 방식으로 통신을 주고받는지에 대한 고려가 필요하다.
2. 백엔드의 통신 구조 : API, Web Server
API(Application Program Interface) : 백엔드끼리 혹은 프론트 엔드와 어떻게 통신을 수행할지 통신 구조에 대하여 설명
3. Logging
Local Server log 혹은 전체 백엔드 시스템의 log를 모아서 관리하는 시스템
4. File Storage
5. Queue
6. DataBase
7. CI/CD
연구결과를 microservice로 통합하기 위해, 현재 제작중이 repogitory에서 기존의 연구 결과를 Docker를 통해 통합하여,
각 연구 결과가 Docker만 존재한다면 어느 환경에서든 실행되고, 이를 Docker Network로 통합하여 서로 간의 일반적인 통신(string, int, float, image 등)은 통신될 수 있도록 구현이 완료되었다.
이러한 프로젝트의 시스템을 monorepo로 만들어 아래 링크에 제작하였다.
문제상황
현재 이 작업을 수행하기 위한 연구원들의 가장 큰 문제점은 백엔드에 대한 전반적인 지식이 부족한 것이다.
개요에 존재하는 ARNA의 현 상황을 해결하기 위해 microservice + gRPC가 효과적인 해결책이 될 수 있겠다는 정보를 찾아냈으나, 이게 정말 최선의 선택인지에 관해 판단할 백엔드에 전반적인 지식을 가진 검토자가 존재하지 않는다.
이러한 문제를 해결하기 위해 백엔드에 대한 지식의 큰 줄기를 만들 필요성이 대두되었다
해결방안
이러한 회사의 제품이 앞으로 변경될 시스템에 따라 관리되야하고, 기본적으로 연구에 관련된 지식에 치중되어, Docker 등과 같은 배포를 위한 세팅이 대부분 수행되지 않은 연구의 결과물을 활용하기 위해서, 백엔드 시스템을 만들 필요성이 대두되었다.
그러나 현재 연구원들중 백엔드 지식을 폭넓게 알고 있는 능력을 가진 연구원은 없는 상태이며, 이러한 문제점을 해결하기 위해
백엔드를 구성하는 다양한 요소를 정리한다.
해당 요소 내에서 어떠한 구체적인 내용들이 있는지를 백엔드 개발자 로드맵을 통해 정리한다.
정리된 각 내용들의 장단점을 분석한다.
위 내용을 기반으로, 우리의 제품이 필요한 요구사항을 정리해보고 각 요소별 최적화, 하드웨어 요구사항, 보안 등의 요소를 고려해 어떤 요소에 어떠한 구성요소를 선택할지 결정한다.
위의 과정을 수행하여, 최적의 백엔드 시스템을 구성해보고 이를 유지/보수가 가능하게 만드는 것이 백엔드 서버를 구현하는 1차적인 목표이다.
이를 수행하기위해 Github Blog에 새로운 BE 탭을 만들어 전체적인 지식에 대해 정리해본다.
참고자료
코딩애플 : 마이크로서비스란 무엇인가
마이크로서비스의 구성요소
기술노트 : 백엔드 정리
-
1차 회의 - 방향성 결정
백엔드 서버를 어떻게 구성할 것인가?
현 진행상황
연구결과를 microservice로 통합하기 위해, 현재 제작중이 repogitory에서 기존의 연구 결과를 Docker를 통해 통합하여,
각 연구 결과가 Docker만 존재한다면 어느 환경에서든 실행되고, 이를 Docker Network로 통합하여 서로 간의 일반적인 통신(string, int, float, image 등)은 통신될 수 있도록 구현이 완료되었다.
이러한 프로젝트의 시스템을 monorepo로 만들어 아래 링크에 제작하였다.
문제상황
현재 이 작업을 수행하기 위한 연구원들의 가장 큰 문제점은 백엔드에 대한 전반적인 지식이 부족한 것이다.
개요에 존재하는 ARNA의 현 상황을 해결하기 위해 microservice + gRPC가 효과적인 해결책이 될 수 있겠다는 정보를 찾아냈으나, 이게 정말 최선의 선택인지에 관해 판단할 백엔드에 전반적인 지식을 가진 검토자가 존재하지 않는다.
이러한 문제를 해결하기 위해 백엔드에 대한 지식의 큰 줄기를 만들 필요성이 대두되었다
해결방안
이러한 회사의 제품이 앞으로 변경될 시스템에 따라 관리되야하고, 기본적으로 연구에 관련된 지식에 치중되어, Docker 등과 같은 배포를 위한 세팅이 대부분 수행되지 않은 연구의 결과물을 활용하기 위해서, 백엔드 시스템을 만들 필요성이 대두되었다.
그러나 현재 연구원들중 백엔드 지식을 폭넓게 알고 있는 능력을 가진 연구원은 없는 상태이며, 이러한 문제점을 해결하기 위해
백엔드를 구성하는 다양한 요소를 정리한다.
해당 요소 내에서 어떠한 구체적인 내용들이 있는지를 백엔드 개발자 로드맵을 통해 정리한다.
정리된 각 내용들의 장단점을 분석한다.
위 내용을 기반으로, 우리의 제품이 필요한 요구사항을 정리해보고 각 요소별 최적화, 하드웨어 요구사항, 보안 등의 요소를 고려해 어떤 요소에 어떠한 구성요소를 선택할지 결정한다.
위의 과정을 수행하여, 최적의 백엔드 시스템을 구성해보고 이를 유지/보수가 가능하게 만드는 것이 백엔드 서버를 구현하는 1차적인 목표이다.
이를 수행하기위해 Github Blog에 새로운 BE 탭을 만들어 전체적인 지식에 대해 정리해본다.
-
-
-
Manage blog comments with Giscus
Giscus is a free comments system powered without your own database. Giscus uses the Github Discussions to store and load associated comments based on a chosen mapping (URL, pathname, title, etc.).
To comment, visitors must authorize the giscus app to post on their behalf using the GitHub OAuth flow. Alternatively, visitors can comment on the GitHub Discussion directly. You can moderate the comments on GitHub.
Prerequisites
Create a github repo
You need a GitHub repository first. If you gonna use GitHub Pages for hosting your website, you can choose the corresponding repository (i.e., [userID].github.io)
The repository should be public, otherwise visitors will not be able to view the discussion.
Turn on Discussion feature
In your GitHub repository Settings, make sure that General > Features > Discussions feature is enabled.
Activate Giscus API
Follow the steps in Configuration guide. Make sure the verification of your repository is successful.
Then, scroll down from the manual page and choose the Discussion Category options. You don’t need to touch other configs.
Copy _config.yml
Now, you get the giscus script. Copy the four properties marked with a red box as shown below:
Paste those values to _config.yml placed in the root directory.
# External API
giscus_repo: "[ENTER REPO HERE]"
giscus_repoId: "[ENTER REPO ID HERE]"
giscus_category: "[ENTER CATEGORY NAME HERE]"
giscus_categoryId: "[ENTER CATEGORY ID HERE]"
-
-
Markdown from A to Z
Headings
To create a heading, add number signs (#) in front of a word or phrase. The number of number signs you use should correspond to the heading level. For example, to create a heading level three (<h3>), use three number signs (e.g., ### My Header).
Markdown
HTML
Rendered Output
# Header 1
<h1>Header 1</h1>
Header 1
## Header 2
<h2>Header 2</h2>
Header 2
### Header 3
<h3>Header 3</h3>
Header 3
Emphasis
You can add emphasis by making text bold or italic.
Bold
To bold text, add two asterisks (e.g., **text** = text) or underscores before and after a word or phrase. To bold the middle of a word for emphasis, add two asterisks without spaces around the letters.
Italic
To italicize text, add one asterisk (e.g., *text* = text) or underscore before and after a word or phrase. To italicize the middle of a word for emphasis, add one asterisk without spaces around the letters.
Blockquotes
To create a blockquote, add a > in front of a paragraph.
> Yongha Kim is the best developer in the world.
>
> Factos 👍👀
Yongha Kim is the best developer in the world.
Factos 👍👀
Lists
You can organize items into ordered and unordered lists.
Ordered Lists
To create an ordered list, add line items with numbers followed by periods. The numbers don’t have to be in numerical order, but the list should start with the number one.
1. First item
2. Second item
3. Third item
4. Fourth item
First item
Second item
Third item
Fourth item
Unordered Lists
To create an unordered list, add dashes (-), asterisks (*), or plus signs (+) in front of line items. Indent one or more items to create a nested list.
* First item
* Second item
* Third item
* Fourth item
First item
Second item
Third item
Fourth item
Code
To denote a word or phrase as code, enclose it in backticks (`).
Markdown
HTML
Rendered Output
At the command prompt, type `nano`.
At the command prompt, type <code>nano</code>.
At the command prompt, type nano.
Escaping Backticks
If the word or phrase you want to denote as code includes one or more backticks, you can escape it by enclosing the word or phrase in double backticks (``).
Markdown
HTML
Rendered Output
``Use `code` in your Markdown file.``
<code>Use `code` in your Markdown file.</code>
Use `code` in your Markdown file.
Code Blocks
To create code blocks that spans multiple lines of code, set the text inside three or more backquotes ( ``` ) or tildes ( ~~~ ).
<html>
<head>
</head>
</html>
def foo():
a = 1
for i in [1,2,3]:
a += i
Horizontal Rules
To create a horizontal rule, use three or more asterisks (***), dashes (---), or underscores (___) on a line by themselves.
***
---
_________________
Links
To create a link, enclose the link text in brackets (e.g., [Blue Archive]) and then follow it immediately with the URL in parentheses (e.g., (https://bluearchive.nexon.com)).
My favorite mobile game is [Blue Archive](https://bluearchive.nexon.com).
The rendered output looks like this:
My favorite mobile game is Blue Archive.
Adding Titles
You can optionally add a title for a link. This will appear as a tooltip when the user hovers over the link. To add a title, enclose it in quotation marks after the URL.
My favorite mobile game is [Blue Archive](https://bluearchive.nexon.com "All senseis are welcome!").
The rendered output looks like this:
My favorite mobile game is Blue Archive.
URLs and Email Addresses
To quickly turn a URL or email address into a link, enclose it in angle brackets.
<https://www.youtube.com/>
<fake@example.com>
The rendered output looks like this:
https://www.youtube.com/
fake@example.com
Images
To add an image, add an exclamation mark (!), followed by alt text in brackets, and the path or URL to the image asset in parentheses. You can optionally add a title in quotation marks after the path or URL.

The rendered output looks like this:
Linking Images
To add a link to an image, enclose the Markdown for the image in brackets, and then add the link in parentheses.
[](https://www.britannica.com/place/La-Mancha)
The rendered output looks like this:
Escaping Characters
To display a literal character that would otherwise be used to format text in a Markdown document, add a backslash (\) in front of the character.
\* Without the backslash, this would be a bullet in an unordered list.
The rendered output looks like this:
* Without the backslash, this would be a bullet in an unordered list.
Characters You Can Escape
You can use a backslash to escape the following characters.
Character
Name
`
backtick
*
asterisk
_
underscore
{}
curly braces
[]
brackets
<>
angle brackets
()
parentheses
#
pound sign
+
plus sign
-
minus sign (hyphen)
.
dot
!
exclamation mark
|
pipe
HTML
Many Markdown applications allow you to use HTML tags in Markdown-formatted text. This is helpful if you prefer certain HTML tags to Markdown syntax. For example, some people find it easier to use HTML tags for images. Using HTML is also helpful when you need to change the attributes of an element, like specifying the color of text or changing the width of an image.
To use HTML, place the tags in the text of your Markdown-formatted file.
This **word** is bold. This <span style="font-style: italic;">word</span> is italic.
The rendered output looks like this:
This word is bold. This word is italic.
Touch background to close
